Hive(八)Hive中的函数
HIVE 的函数
hive 中有很多强大的计算函数,这在进行统计计算中是很有用的,而且支持通过代码的方式来自定义函数,非常的灵活。
函数的wiki文档连接 <LanguageManual UDF - Apache Hive - Apache Software Foundation>
查看函数和用法
除了通过文档查看,也有命令可以查看系统函数的使用方法
- 查看支持的函数
1 | show fucntions |
可以看到内置了非常多的函数。
查看某个函数的详细用法
1
desc function extended abs;

输出内容中显示了函数的使用实例和说明
常用函数
NVL
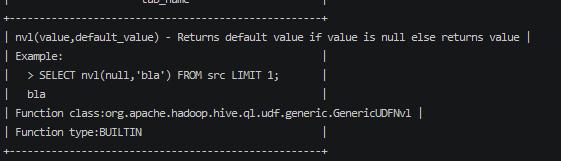
此函数可以为一个为null的列赋值一个默认值;
1 | select nvl(comm,'123') from emp; |
当comm 为null的时候,默认值为 ‘123’;
CASE WHEN THEN ELSE END
desc function extends case;
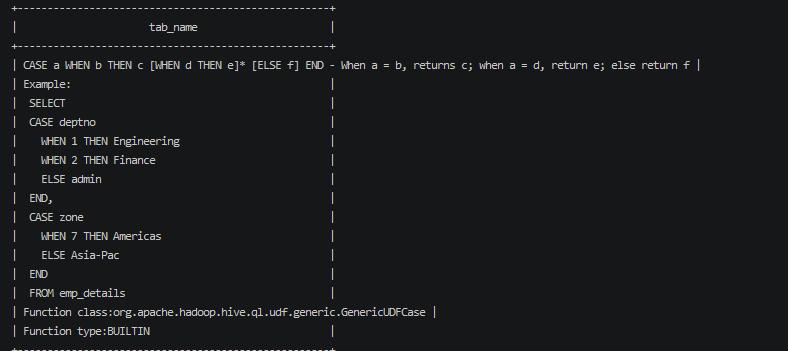
此函数对值做逻辑判断处理
split
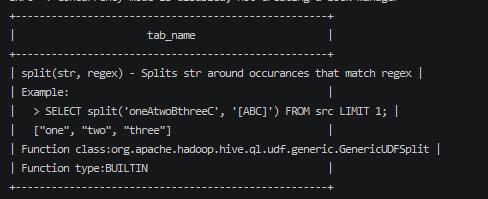
此函数对结果进行split 分割;
substring;
字符串分割函数
1 | SELECT substring('Facebook', 5,2) FROM emp LIMIT 1; |
//结果
1 | bo |
IF
判断函数
此函数有3个值。**IF(expr1,expr2,expr3) **
根据expr1 是true 或false 分别显示 expr2 或expr3
1 | select IF(1==1,'对','错') from emp limit limit 1; |
+——+
| _c0 |
+——+
| 对 |
+——+
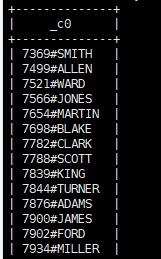
CONCAT
用来连接几个参数
1 | select CONCAT(empno,'#',ename) from emp; |
结果
CONCAT_WS
CONCAT_WS(‘.’, ‘www’, array(‘facebook’, ‘com’))
此函数通过第一个参数,连接后面的字符串或数组,通过第一个参数分割连接。
在执行此函数的时候会提示 CONCAT_WS must be “string or array
注意参数必须是字符串类型或字符串的数组。
COLLECT_SET
此函数将某个列的结果去重生成一个数组集合。只支持基本的类型。
1 | select collect_set(job) from emp; |
1 | +----------------------------------------------------+ |
EXPLODE
将列中复杂的结构 array 或 map拆成多行展示。
创建表
1
create table user_info( name string, friends array<string> )row format delimited fields terminated by ',' collection items terminated by '_' lines terminated by '\n';
插入数据
1
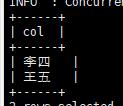
insert into user_info(name,friends ) values ('张三',array('李四','王五'));
将数据拆平展示
1 | select explode(friends) from user_info; |
窗口函数 OVER()
在执行查询的时候会得到一个结果表格。在此结果集的基础上,划定一个窗口也就是数据范围,针对此数据范围做对应的函数计算。
窗口函数可以理解为 针对每一行的在查询数据结果中指定的一个数据计算的范围。
窗口函数式跟每一行相关的
创建函数的关键字为 OVER
最简单的窗口函数
1 | select f ,count(*) over() from table; |
这是一个窗口函数的最简单的应用,查询了某个字段并查询了窗口中的数据总量。
需要注意的是窗口是针对每一个行开的
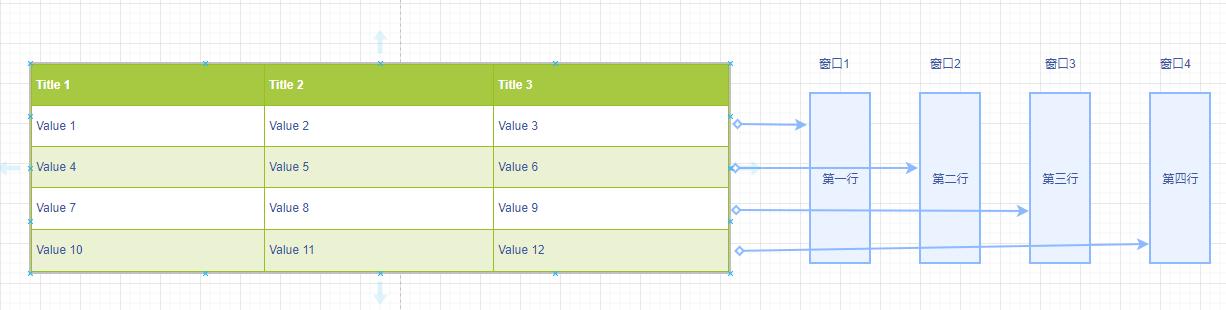
行与窗口的关系;
< https://www.jianguoyun.com/p/DVSt59IQ35O6ChiN_70EIAA>
默认的开窗范围是全部数据范围,同时支持一些参数来控制这个范围
CURRENT ROW:表示当前行
n PRECEDING:表示往前n行数据
n FOLLOWING:表示往后n行数据
UNBOUNDED:表示起点,
UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED FOLLOWING表示到后面的终点
LAG(col,n,default_val):往前第n行数据 ,有个默认值,作用是如果是第一行是没有前n 行的,就返回默认值
LEAD(col,n, default_val):往后第n行数据
NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始。获取窗口的编号
示例
测试数据
1 | jack,2017-01-01,10 |
创建表,并导入数据
1 | create table business( |
1 | load data local inpath "/home/hadoop/business.txt" into table business; |
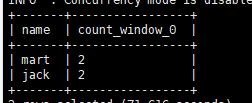
查询在2017年4月份购买过的顾客及总人数
筛选出4月份的数据,根据姓名聚合得到姓名的集合,然后使用开窗函数统计总数
1 | select name , count(*) over() from business where orderdate >= '2017-04-01' and orderdate < '2017-05-01' group by name; |
结果:
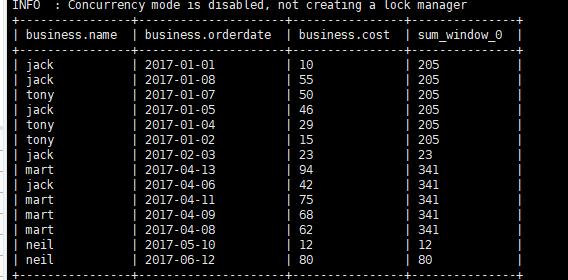
查询顾客的购买明细及月购买总额
展示每个顾客的明细需要输出原数据,每个顾客的月购买总额对 当月的数据进行开窗。
1 | select * ,sum(cost) over(partition by month(orderdate)) from business; |
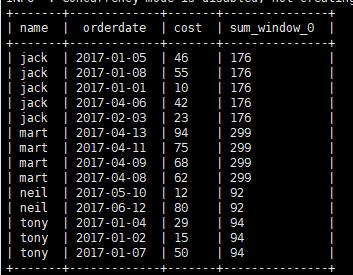
将顾客的cost 进行累加
要对每个顾客进行求和可以使用语句
1 | select name,orderdate,cost,sum(cost) over(partition by name) from business; |
通过partition by 对每个窗口中的数据范围进行区分,会得到每个分区的求和结果
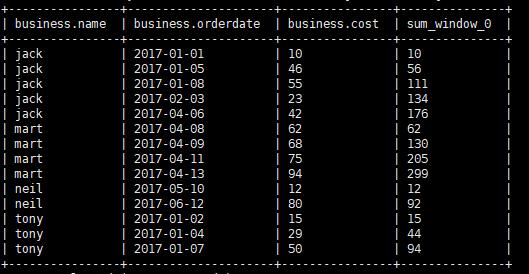
而如果要得到每个人不是求总是而是累加的效果;累加就是 组内 当前行之前的范围
所以
1 | select *,sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING AND current row) from business; |
ROWS BETWEEN 表示在开窗中行数限制的指令
直接使用
1 | select *,sum(cost) over(partition by name order by orderdate ) from business; |
去掉了 rows between UNBOUNDED PRECEDING AND current row 能得到同样的效果,
是因为开窗函数中默认的order by 后面就锁定了开始到当前行的范围。
这里主要对开窗行数的数据范围急性控制达到想要的目的。
当前行到前面一行和后面一行求平均值
同样使用行数的范围控制
1 | select *,avg(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) from business; |
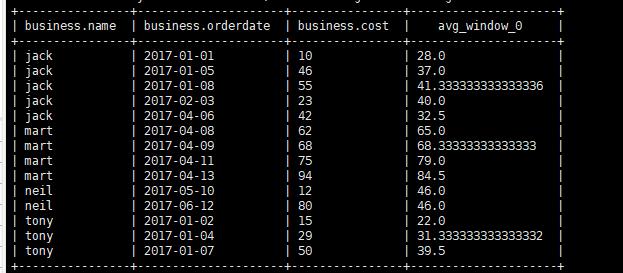
当前行到最后行求最小值
1 | select *,min(cost) over(partition by name order by orderdate rows between current row AND UNBOUNDED FOLLOWING ) from business; |
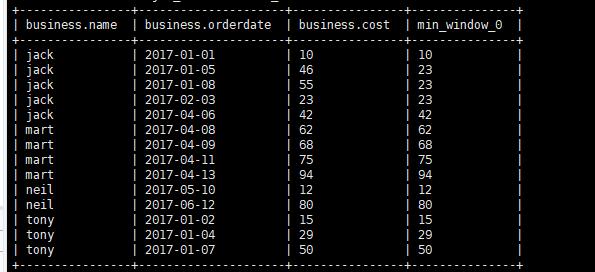
查看顾客上次购买的时间
查看某个顾客上次购买的时间,先根据时间排序然后 需要利用LAG 函数;
1 | select name , orderdate, lag(orderdate,1,'1970-01-01') over(partition by name order by orderdate ) from business; |
通过lag函数获取前一条数据,同时开窗函数根据名称分区根据时间排序。
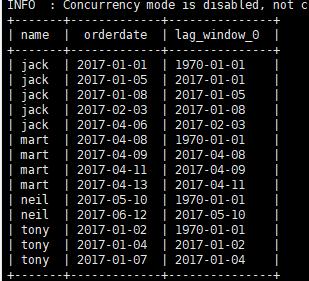
前百分20 的订单信息
此需求可以利用 NTILE 函数,先根据时间分区,然后获取指定组的数据。
ntile 其实本质上只会对结果中的数据加个编号,如果指定组只有2 ,那么平均分2份,前面标记1 ,后面标记为2;
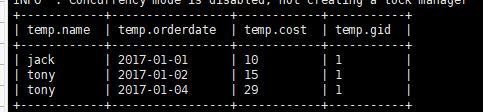
1 | select * ,ntile(5) over(order by orderdate) gid from business; |
这种查询的结果将总结果的数量分为了5份,会得到这样的结果
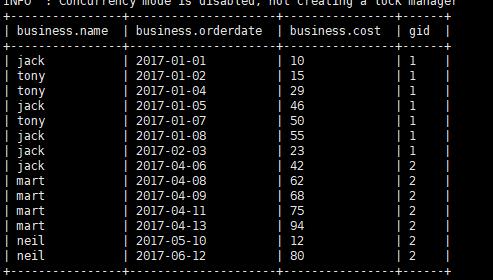
那么针对此结果进行过滤能够得到前20% 的数据
1 | select * from (select * ,ntile(5) over(order by orderdate) gid from business) temp where temp.gid =1; |
得到结果:
RANK
rank 函数用来处理排名的显示;
针对不同的需求,提供了
- RANK 排序的时候相同的会重复,总数不会变
- DENSE_RANK() 排序相关会重复,总数会减少
- ROW_NUMBER() 会根据顺序计算
测试数据
1 | 孙悟空 语文 87 |
创建表
1 | create table score( |
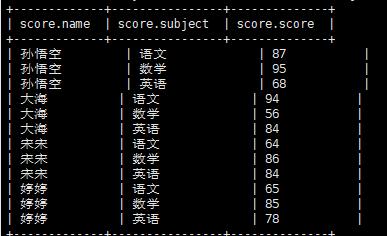
加载数据
1 | load data local inpath "/home/hadoop/data/score" into table score; |
导入数据结果
查询排名情况
1 | select *,RANK() over(order by score) rank1, DENSE_RANK() over(order by score) rank2 , ROW_NUMBER() over(order by score) rank3 from score; |
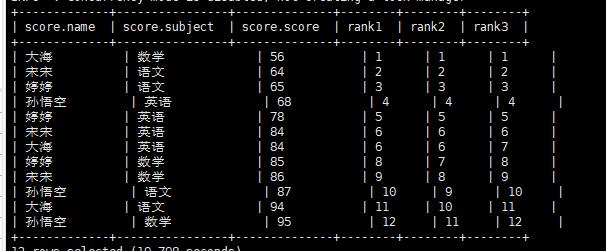
执行结果
查询各个科目的总和的排名情况
1 | select *,rank() over(order by total_score ) from ( select name, sum(score) as total_score, rank() over() from score group by name) tmp; |
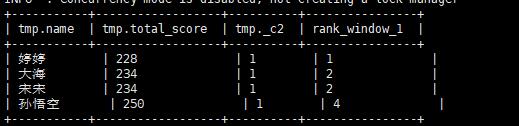
查询各个科目的单独的排名情况
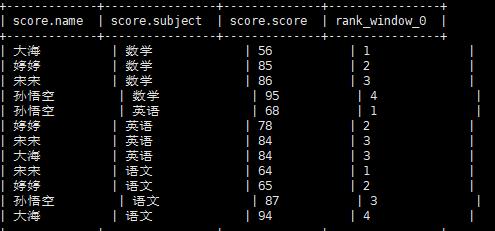
1 | select *,rank() over(partition by subject order by score ) from score; |
自定义函数
虽然hive自带了很多的函数,但是为了更加的灵活处理数据,hive允许用户通过自定义函数的方式进行扩展。
HIVE 自定义函数: <HivePlugins - Apache Hive - Apache Software Foundation>
自定义函数的分类
UDF User-Defined-Function 一行入参出一结果,例如nvl函数,pi函数
自定义继承类 org.apache.hadoop.hive.ql.udf.generic.GenericUDF
UDAF User-Defined-Aggreget Function 多行入参出一个结果,类似于 max、
min、avg这些。
自定义继承类 org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver
UDTF User-Defined-Table-Generating Function 一行入参出多个结果。例如
lateral view explode()
自定义继承类 org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
自定义函数
建立maven 工程 引用对应的版本依赖
1
2
3
4
5<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>编写函数类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public class Lower extends GenericUDF {
//初始化校验
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length != 1) {
throw new UDFArgumentException("参数数量不等于1");
}
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
//函数解析
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
DeferredObject argument = arguments[0];
Object value = argument.get();
if(value == null){
return null;
}
return value.toString().toLowerCase(Locale.ROOT);
}
//一般返回空字符串就行,用在explain中的显示
@Override
public String getDisplayString(String[] children) {
return "";
}
}打包并上传到服务器
hive中执行jar包引入
hive 命令中执行;
1
2
3
4add jar /home/hadoop/data/hive-function-1.0-SNAPSHOT.jar;
//查看已经引入的jar包
list jar;创建一个临时函数
1
2create temporary function my_lower as "com.hivedemo.function.Lower";

执行自定义函数
1
2select my_lower('AbC') from business limit 1;