
Hive(二)Hive安装
Hive 的安装
hive 和 hadoop版本关系
hive使用的前提是安装hadoop。版本的对应关系一定要对,不然可能出现各种因为版本不兼容的问题。

我们 之前安装的hadoop版本是 3.1.3.
所以hive也要选中 3.x版本;
hive 也分为2.x 和3.x 版本;
目前hive最新版本3.1.3 ,直接使用此版本.
为了确认版本的一致,可以去github 中的 hive项目的依赖中找到对应的hadoop版本
github 地址 https://github.com/apache/hive
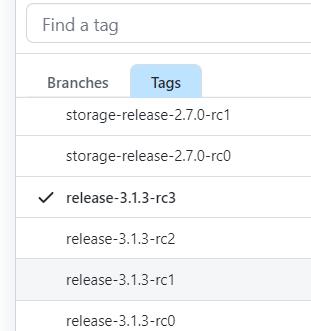
找到对应的tag
查看pom.xml
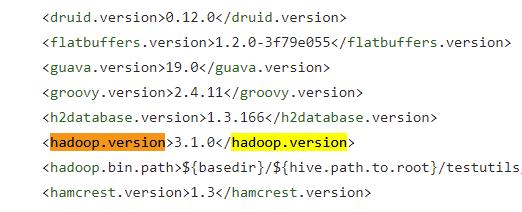
搜索hadoop.verion 可以查看依赖的版本。
基础环境
目前3台机器 hadoop1 hadoop2 hadoop3
hadoop1 安装了 hdfs NameNode 3台都安装了hdfs的 DataNode
hadoop2 安装了yarn 的 ResouceManger ,3 台都安装了yarn的 NodeManager
安装hive之前hadoop是必须要安装的 安装参考链接 https://blog.ponyo.website/archives/dbeadcf1.html
下载地址
下载地址https://dlcdn.apache.org/hive/
https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
安装HIVE
上传安装包
在hadoop1 机器上操作 (普通用户操作 hadoop )
1 | cd /usr/local/software |
上传jar包到目录
1 | tar -zxvf apache-hive-3.1.3-bin.tar.gz |
1 | drwxrwxr-x. 3 hadoop hadoop 157 4月 28 06:00 bin |
可以看到基本的结构
bin 目录执行文件
conf 配置文件
examples 示例程序
hcatalog hcatalog 管理表和元数据的服务程序
lib 程序jar包
scripts 脚本文件
配置环境变量
目前安装目录为 /usr/local/software/hive/apache-hive-3.1.3-bin
1 | sudo vim /etc/profile.d/my_env.sh |
编辑环境变量文件
添加内容
1 |
|
1 |
|
重新使用环境变量
修改hive配置文件
进入到hive的 /conf 目录下
1 | mv hive-env.sh.template hive-env.sh |
生成 hive-env.sh 文件
添加内容
1 | HADOOP_HOME=/usr/local/software/hadoop/hadoop-3.1.3 |
写入内容,配置hadoop的home 目录,和hive的配置目录.
尝试启动
默认的数据库是用的derby,如果使用作为数据库的话,就执行下面的数据库初始化脚本
1 | bin/schematool -dbType derby -initSchema |
执行后可能出现错误.
1 | SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] |
这应该是google guava 的jar包版本问题,需要从hadoop的 lib目录中把 jar包拷贝过来。
目录hive中的是 9 guava-19.0.jar
hadoop 中的是 guava-27.0-jre.jar
1 | cp /usr/local/software/hadoop/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/software/hive/apache-hive-3.1.3-bin/lib/ |

再次执行初始化 derby 数据
1 | bin/schematool -dbType derby -initSchema |
1 | 当看到执行完成,没有报错,就表示已经执行完毕了. |
1 |
|
执行 次命令可直接启动
配置mysql存储元数据
虽然hive内置了derby ,但是不推荐使用,因为对于derby的元数据存储方案,那么数据文件和和hive程序绑定的,假如在其他的机器节点上也装了一个hive,那么将无法获取之前的数据,无法做到数据的集中的管理。
所以让hive能够连接mysql进行数据的元数据管理。
这里为了简单,快速,使用docker的方式安装mysql。(前提,机器已经安装了docker的环境,并且生产环境不推荐数据库使用容器来装)
docker 的快速安装 https://blog.ponyo.website/archives/9bc1bdf5.html#docker%E5%AE%89%E8%A3%85
创建mysql的数据目录和配置目录,和日志目录
1 | mkdir -p /usr/local/software/mysql/conf |
1 | sudo docker run --name mysql-5.7 -v /usr/local/software/mysql/conf:/etc/mysql/conf.d -v /usr/local/software/mysql/logs:/logs -v /usr/local/software/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=111111 -d -p 3306:3306 mysql:5.7 |
1 | sudo docker ps |

1 | sudo docker exec -it b2f70bec8375 /bin/bash |
进入容器内部.检查连接是否正常
1 | mysql -u root -p |

至此,mysql安装成功。
配置hive使用mysql连接。
hive 下是没有mysql的连接驱动包的,需要手动放到lib目录下。
1 | wget -O /usr/local/software/hive/apache-hive-3.1.3-bin/lib/mysql-connector-java-8.0.21.jar https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.21/mysql-connector-java-8.0.21.jar |

在hive 的 conf下新建配置文件 。
1 | vim hive-site.xml |
1 | <?xml version="1.0"?> |
- 配置使用mysql和mysql的一些信息
- 配置了元数据的存储信息
- 配置了hive在hdfs的工作目录
在hdfs上创建默认的工作目录。
1 | hadoop fs -mkdir /tmp |
hive 执行的时候,会用到这2个目录,其中 /user/hive/warehouse 在上面的 hive-size.xml 中已经做了配置
hive 配置完毕后,初始化数据到mysql ,然后就可以启动了
配置的连接的数据库是 metastore 数据库.
那么需要先手动登录进去创建一个这个数据库.
1 | create DATABASE metastore; |
数据库建立完毕后,可以初始化表结构等数据了。
1 | bin/schematool -dbType mysql -initSchema |
注意:这里指定的dbType
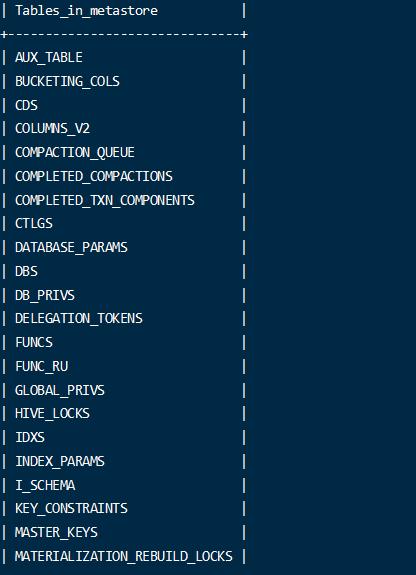
初始化完成后,会向数据库中创建需要的记录元数据的表。
1 | //使用此命令启动 |
beeline 介绍
Beeline是 Hive 0.11版本引入的新命令行客户端工具,它是基于SQLLine CLI的JDBC客户端。
通过beeline 可以很好的连接hive服务。
Beeline⼯作模式有两种,即嵌⼊模式和远程模式。嵌⼊模式情况下,它返回⼀个嵌⼊式的Hive(类似于Hive CLI)。⽽远程模式则是通过
Thrift协议与某个单独的HiveServer2进程进⾏连接通信。在远程模式下hiveserver2只接受thrift的接⼝调⽤,即使是http模式,它⾥⾯也是包含thrift 信息的。所以可以看到后面的配置中需要配置thrift信息。
配置服务方式访问
目前的hive只是一个本机的命令行工作来使用,而需要将其配置成服务的方式,让其他的机器也能通过远程来访问。
- hive-site.xml 添加配置
1 | <property> |
配置hive 的元数据服务要访问的hdfs 地址。
- 添加server配置
1 | <property> |
这个配置是需要配置一个 server2的服务.
因为 metastore 是用来接收元数据的访问请求信息。
server2服务是 接收客户端的访问请求信息,有个2是以为之前有个1版本。
参考链接: https://blog.csdn.net/liusuoyin/article/details/108206976
所以需要启动2个服务
- 先后台启动一个元数服务信息
1 | nohup hive --service metastore 2>&1 & |
- 再启动一个 server2 的服务
1 | nohup hive --service hiveserver2 2>&1 & |
通过 ps -ef | grep hive 看到后台已经启动了2个进程。
- 使用beeline 客户端连接。beeline 是内置的命令行客户端可以有更好的显示,支持远程连接。
1 | beeline -u jdbc:hive2://hadoop1:10000 -n root |
1 | Error: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop1:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hadoop is not allowed to impersonate root (state=08S01,code=0) |
访问的时候出现这个错误的原因是 root 用户未通过hadoop的权限验证,需要在hadoop中配置上此用户。
编辑 hadoop core-site.xml
1 | <property> |
需要注意下,这个访问用户需要拥有hdfs /tmp 节点的权限,不然是无法访问的
1 | Could not open client transport with JDBC Uri: jdbc:hive2://hadoop1:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=EXECUTE, inode="/tmp":hadoop:supergroup:drwxrwx--- |
报错信息,所以根据据具体的情况选用用户访问。或修改hdfs中的目录的权限归属 hadoop fs -chown -R
重启hadoop 再次执行上面的连接命令,使用hadoop用户
1 | beeline -u jdbc:hive2://hadoop1:10000 -n hadoop |
和基本的mysql的sql 是差不多的;
1 | show databases; |
配置hive日志
因为当前的启动用户是hadoop用户,所以默认日志目录在
/tmp/hadoop/hive.log
要是别的用户就是
/tmp/xxxx/hive.log

修改方式:
- conf 下 log4j2.properties.template 复制成为hive-log4j2.properties
1 | mv hive-log4j2.properties.template hive-log4j2.properties |
修改属性
vim hive-log4j2.properties
property.hive.log.dir = /usr/local/software/hive/apache-hive-3.1.3-bin/logs

- 重启hive ,观察日志存放位置即可
其他设置配置
命令行的set 命令可以打印所有的配置信息
并可以通过set进行设置,不过此设置只对当前的本次执行的操作是有效的。长久的有效还是需要修改配置文件.
1 | set mapred.reduce.tasks=10; |
有很多的参数可以设置;此设置可以根据需要配置成永久生效或临时生效。
