查询 支持基本ql的相关语法。
官方文档 https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select
基本查询格式
1 2 3 4 5 6 7 8 9 10 11 [WITH CommonTableExpression (, CommonTableExpression)*] (Note: Only available starting with Hive 0.13.0) SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [ORDER BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ] [LIMIT [offset,] rows]
测试数据准备 创建员工表和部门表
dept
1 2 3 4 5 6 7 10 ACCOUNTING 1700 20 RESEARCH 1800 30 SALES 1900 40 OPERATIONS 1700
emp
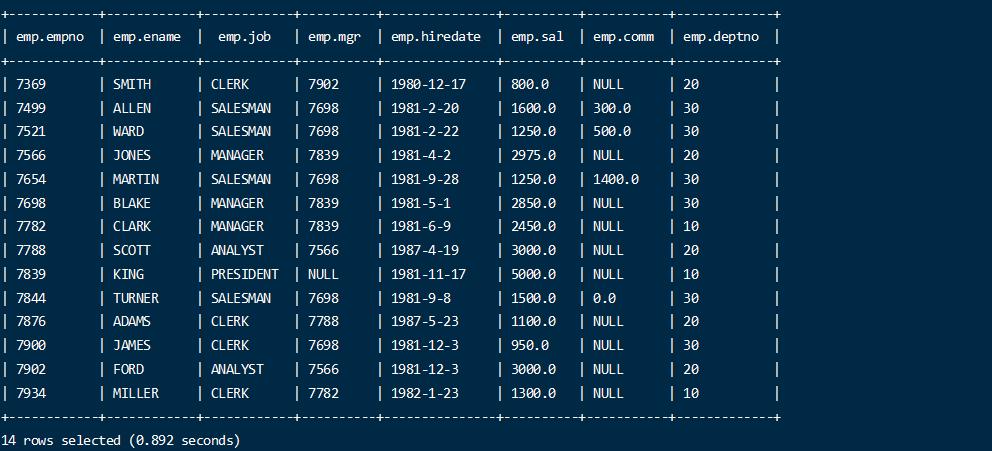
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 7369 SMITH CLERK 7902 1980-12-17 800.00 20 7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30 7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30 7566 JONES MANAGER 7839 1981-4-2 2975.00 20 7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30 7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30 7782 CLARK MANAGER 7839 1981-6-9 2450.00 10 7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20 7839 KING PRESIDENT 1981-11-17 5000.00 10 7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30 7876 ADAMS CLERK 7788 1987-5-23 1100.00 20 7900 JAMES CLERK 7698 1981-12-3 950.00 30 7902 FORD ANALYST 7566 1981-12-3 3000.00 20 7934 MILLER CLERK 7782 1982-1-23 1300.00 10
1 2 3 4 5 6 create table if not exists dept( deptno int, dname string, loc int ) row format delimited fields terminated by '\t';
1 2 3 4 5 6 7 8 9 10 11 create table if not exists emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) row format delimited fields terminated by '\t';
数据导入
1 2 3 load data local inpath '/home/hadoop/data/dept' into table dept; load data local inpath '/home/hadoop/data/emp' into table emp;
数据准备完成
基本操作 列别名 as
运算符 A%B A对B取余 A&B A和B按位与 A|B A和B按位或 A^B A和B按位异或 ~A A按位取反 A / B A - B A<=>B 如果A和B都为NULL返回true,如果一边为NULL返回false 查询的时候可以执行
select A / 3 as num from xx; 得到对应的计算结果
比较运算 A=B 基本数据类型 如果A等于B则返回TRUE,反之返回FALSE A<=>B 基本数据类型 如果A和B都为NULL,则返回TRUE,如果一边为NULL,返回False A<>B, A!=B 基本数据类型 A或者B为NULL则返回NULL;如果A不等于B,则返回TRUE,反之返回FALSE A<B 基本数据类型 A或者B为NULL,则返回NULL;如果A小于B,则返回TRUE,反之返回FALSE A<=B 基本数据类型 A或者B为NULL,则返回NULL;如果A小于等于B,则返回TRUE,反之返回FALSE A>B 基本数据类型 A或者B为NULL,则返回NULL;如果A大于B,则返回TRUE,反之返回FALSE A>=B 基本数据类型 A或者B为NULL,则返回NULL;如果A大于等于B,则返回TRUE,反之返回FALSE A [NOT] BETWEEN B AND C 基本数据类型 如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 A IS NULL 所有数据类型 如果A等于NULL,则返回TRUE,反之返回FALSE A IS NOT NULL 所有数据类型 如果A不等于NULL,则返回TRUE,反之返回FALSE IN(数值1, 数值2) 所有数据类型 使用 IN运算显示列表中的值 A [NOT] LIKE B STRING 类型 B是一个SQL下的简单正则表达式,也叫通配符模式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母’x’结尾,而‘%x%’表示A包含有字母’x’,可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 A RLIKE B, A REGEXP B STRING 类型 B是基于java的正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 1 2 3 4 5 6 7 8 9 10 11 select ename = 'SMITH' from emp limit 2; +--------+ | _c0 | +--------+ | true | | false | +--------+
where 操作 1 2 select * from emp where comm is not null and hiredate > '1981-2-22';
+————+————+———–+———-+—————+———-+———–+————-+
基本函数 count() avg() min() sum() avg() 支持sql的基本函数,同时也支持复杂的自定义函数,后面说明。
like Rlike 操作 like 表示基本的模糊查询;
_ 表示一个匹配符,% 代表多个匹配符,和mysql的sql 是不一样的。
like 操作 1 2 select * from emp where ename like 'S_ITH';
+————+————+———-+———-+—————+———-+———–+————-+
1 select * from emp where job like 'SA%';
+————+————+———–+———-+—————+———-+———–+————-+
Rike 操作 1 2 select * from emp where ename rlike '^W.+D$';
+————+————+———–+———-+—————+———-+———–+————-+
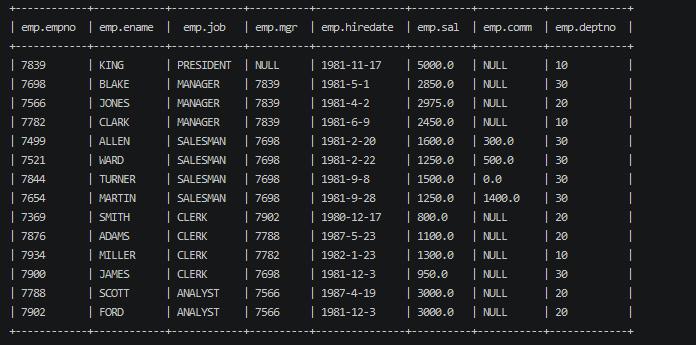
分组 计算部门的平均工资 1 2 select deptno as dno , avg(mgr) as mgr from emp group by deptno;
+——+———+
分组后,可以加having语句进行过滤。
join 连接查询 基本使用 1 2 select * from emp e left join dept d on e.deptno = d.deptno;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 +----------+----------+------------+--------+-------------+---------+---------+-----------+-----------+-------------+--------+ | e.empno | e.ename | e.job | e.mgr | e.hiredate | e.sal | e.comm | e.deptno | d.deptno | d.dname | d.loc | +----------+----------+------------+--------+-------------+---------+---------+-----------+-----------+-------------+--------+ | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 | 20 | RESEARCH | 1800 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 | 30 | SALES | 1900 | | 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 | 30 | SALES | 1900 | | 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 | 20 | RESEARCH | 1800 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 | 30 | SALES | 1900 | | 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 | 30 | SALES | 1900 | | 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 | 10 | ACCOUNTING | 1700 | | 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 | 20 | RESEARCH | 1800 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 | 10 | ACCOUNTING | 1700 | | 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 | 30 | SALES | 1900 | | 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 | 20 | RESEARCH | 1800 | | 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 | 30 | SALES | 1900 | | 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 | 20 | RESEARCH | 1800 | | 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 | 10 | ACCOUNTING | 1700 | +----------+----------+------------+--------+-------------+---------+---------+-----------+-----------+-------------+--------+
连接语法 left join
rigth join
满外连接 full join
满外连接会返回where 的所有的记录值,如果某个值没有符合的数据就返回 null值
使用满连接会将数据都显示出来
1 2 select * from emp e full join dept d on e.deptno = d.deptno;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 +----------+----------+------------+--------+-------------+---------+---------+-----------+-----------+-------------+--------+ | e.empno | e.ename | e.job | e.mgr | e.hiredate | e.sal | e.comm | e.deptno | d.deptno | d.dname | d.loc | +----------+----------+------------+--------+-------------+---------+---------+-----------+-----------+-------------+--------+ | 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 | 10 | ACCOUNTING | 1700 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 | 10 | ACCOUNTING | 1700 | | 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 | 10 | ACCOUNTING | 1700 | | 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 | 20 | RESEARCH | 1800 | | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 | 20 | RESEARCH | 1800 | | 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 | 20 | RESEARCH | 1800 | | 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 | 20 | RESEARCH | 1800 | | 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 | 20 | RESEARCH | 1800 | | 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 | 30 | SALES | 1900 | | 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 | 30 | SALES | 1900 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 | 30 | SALES | 1900 | | 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 | 30 | SALES | 1900 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 | 30 | SALES | 1900 | | 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 | 30 | SALES | 1900 | | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | 40 | OPERATIONS | 1700 | | 8000 | smi | CLERK | 200 | 2021-01-01 | 10.0 | NULL | 100 | NULL | NULL | NULL | +----------+----------+------------+--------+-------------+---------+---------+-----------+-----------+-------------+--------+
注意: 在多个表连接的时候,每个连接都会产生一个MR job,所有关联几个表需要启动几个mr job,不过如果多个表的连接键相同的话,只会启动同一个mr job程序。
排序操作 基本排序 order by xx [desc | asc ]
sort By 排序 order by 排序是全局排序,如果是多个分区 的数据,也是全部获取进行排序,而reduce job中的key 本身就是有序的,当不需要全局排序只需要分区有序的时候,
设置2个job
1 2 3 set mapreduce.job.reduces=2;
执行排序操作
1 select * from emp sort by deptno desc;
可以看到结果 呈 2个排序结果 100 -10 30 -10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 +------------+------------+------------+----------+---------------+----------+-----------+-------------+ | emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno | +------------+------------+------------+----------+---------------+----------+-----------+-------------+ | 8000 | smi | CLERK | 200 | 2021-01-01 | 10.0 | NULL | 100 | | 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 | | 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 | | 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 | | 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 | | 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 | | 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 | | 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 | | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 | | 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 | +------------+------------+------------+----------+---------------+----------+-----------+-------------+
将结果导出可更明显的看到
1 insert overwrite local directory '/home/hadoop/sortby-result' select * from emp sort by deptno desc;
生成2个文件.文件内有序;
分区 Distribute By 在sort by 操作的时候,并不能执行根据什么进行分区,而通过Distribute By 可以指定分区的键,和mr 中的martition 类似;
1 set mapreduce.job.reduces=5;
1 select * from emp distribute by job sort by mgr desc;
观察结果,可以看到mgr 是在每个job上降序的。
注意一定要设置job的 reduces 数量才会有此效果
Cluster By 当distribute by 和sort by 是同一个字段的时候,可以直接使用cluster by
cluster by A = distribute by A sort by A asc;
注意:Cluster By 只能是升序,不能是降序。
1 2 select * from emp cluster by job;