
Hive(一)Hive基本介绍和说明
hive 基本介绍
概述
hive 是什么
借用百度百科的一段话
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
在使用hadoop 操作数据的过程中,操作是比较复杂的,需要自己定义map reduce程序,定义其中的参数的一些细节.而hive 可以通过使用SQL的方式(HQL),hive将用户的sql语句解析并转化成MapReduce程序,处理数据结果,方便了对数据的查询和统计,提高了效率。
hive 是apache的项目,最早由facebook开源。
hive 的官网 http://hive.apache.org/
hive 的基本架构
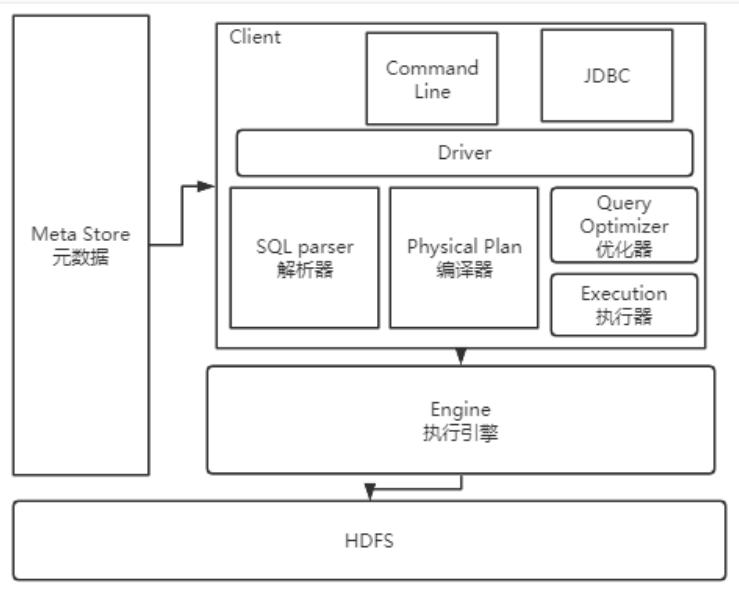
hive 使用jdbc的方式来管理数据。数据的内容分为2部分,一个是元数据,一个是 文件数据。
元数据 类似于mysql的表的 schema 信息,存储了有哪些数据库,有哪些表,表的结构是什么样子的。hive的元数据和数据是分开存储的,
元数据默认是 存在内嵌的数据库(debey)中,当然也可以配置其他的jdbc数据库来存储。
而数据 是存在hdfs中,在hdfs以文件的形式进行存储。类似于mysql的执行sql的过程一样,hive 发出的sql语句 ,要通过sql 解析器,编译器,优化器,执行器,最终调用执行引擎。
执行引擎 默认的是 mapreduce,这个执行引擎是可以进行选择的,也可以选择 Tez、 Spark。在hive 3.x 版本已经不推荐使用MapReduce 作为执行引擎了。
执行引擎可以选择其他的组件,但是文件存储是一定要选用hadoop的hdfs。
优缺点
优点
- 操作接口采用类SQL语法,提供快速开发的能力。
- 避免了去写MapReduce,减少开发人员的学习成本。
- Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。(小数据处理的消耗可能小于启动MR程序的消耗)
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点
Hive的HQL表达能力有限
- 迭代式算法无法表达(MapReduce本身就不支持)
- 数据挖掘方面不擅长
Hive的效率比较低
- Hive自动生成的MapReduce作业,通常情况下不够智能化
- Hive调优比较困难,粒度较粗
