
Hive(四)Hive分区表
分区表
默认的 创建一个数据库 对应着一个hdfs 文件夹,创建一个表 对应着一个hdfs文件夹。
而分区表,是在表的文件夹下 再创建多个子文件夹。通过指定的条件,将多个不同属性的数据分割到多个子目录中。主要用来拆分大的数据文件为多个小的数据文件。
使用分区表
- 创建一个分区表
1 |
|
创建日志表,根据日期进行分区
- 插入多个测试数据
1 |
|
- 可以看到在表下的目录创建了多个带着条件的目录存放分别分区的数据

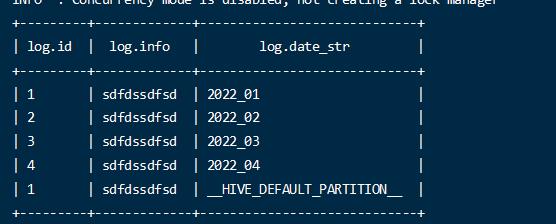
注意:当不指定分区的时候,数据会到默认分区中。 HIVE_DEFAULT_PARTITION
- 查询数据
1 | select * from log; |
默认查询数据会从所有分区中加载数据。
1 | select * from log where date_str= '2022_01'; |
带着分区条件属性查询.
尽量将分区条件设置为经常需要查询的条件。
二级分区
分区的字段,可以指定多个,在分区目录下再增加子目录的方式进行管理.
1 | create table table_partition( |
天和小时 的2级分区。
分区表的管理
为一个表删除分区
1 | alter table log drop partition(date_str='2022_01'); |
删除指定的一个分区。
注意:这个分区内的数据也被删除
为一个表添加分区
1 | alter table log add partition(date_str='2022_01'); |
添加分区后将创建一个分区文件夹
查看分区信息
1 |
|
直接上传到分区目录,如何让hive感知到数据存在
指的是先在hdfs 手动创建好分区目录,而hive的metastore 中还没有此分区信息的情况下
- hdfs目录手动创建,分区目录也创建了,数据也导入到分区了
1 | msck repair table log; |
执行此目录修复
- 手动执行添加分区命令
1 | alter table log add partition(date_str='2022_01'); |
- 在导入数据的时候指定分区
1 | load data local inpath '/log.log' into table |
根本就在于在hive感知到分区的存在。
动态分区
上面的分区的字段和对应的值都是固定的,而有时候并不清楚具体的分区值有多少个。期望能够通过数据的值自动完成分区。类似于mysql动态分表的功能。
动态分区配置
动态分区相关的配置
- 开启配置
hive.exec.dynamic.partition=true 默认是开启的
- 默认是严格模式,严格模式下 必须指定一个分区是静态的分区,所以要使用动态的要设置为非严格模式
hive.exec.dynamic.partition.mode=nonstrict
- 在所有执行MR的节点上,最大一共可以创建多少个动态分区。默认1000
hive.exec.max.dynamic.partitions=1000
- 在每个执行MR的节点上,最大可以创建多少个动态分区,需要预估数据的动态分区的数量,不然会报错
hive.exec.max.dynamic.partitions.pernode=100
- MR job 中,最多可以创建多少个hdfs文件 默认 100000
hive.exec.max.created.files=100000
- 分区为空的时候,是否抛异常,没有分区字段值的时候
hive.error.on.empty.partition=false
以上的这些设置,可以修改 hive-site.xml 永久生效。如果需要改的话。
也可以在命令行中使用set 命令,只针对本次使用生效。
1 | set hive.exec.dynamic.partition.mode=nonstrict; |
动态分区使用
创建一个员工表,根据部门id 动态分区
···
create table emp( id int, name string)partitioned by (dept_id int) row format delimited fields terminated by ‘,’;
···向表中插入数据
1 | insert into emp(id,name,dept_id) values (1,'名字1',1); |
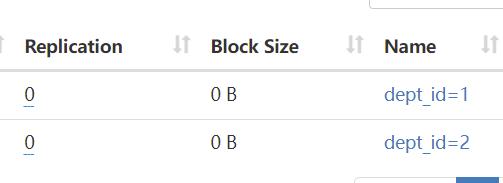
可以看到已经自动帮做了分区。
采用动态分区后,很多种情况会产生mr计算的过程。比静态分区会多很多的计算。
