
Hive(三)Hive字段类型和DDL操作
hive的sql基本使用和mysql是很像的。也有对应的数据类型字段等信息;
在metastore 中的 存储了描述了数据类型的相关的信息。
hive 中的字段类型
简单的数据类型对应关闭
1 | Hive数据类型 JAVA数据类型 长度 |
- 数据类型和mysql是差不多,字符类型只有一个是STRING 类型,不区分长度的,最大可以到2GB
- 整数类型有好几种类型,我们预估数据的长度选择合适的类型,与mysql不一样的是,即使数据超过了长度也不会报错,内部最自动对长度进行提升,选用小的可以在计算的时候开辟更小的内存。
- 支持类型转换函数,可以在查询的是将数据类型进行转换
复杂数据类型
STRUCT
类似于java中的一个对象的数据结构; structstreet:string,city:string
在查询的是可以使用 . 的方式进行访问
select user.age from dept
MAP
map<string,int>
select prop[‘xx’] from xx
ARRAY
[“A”,”B”,”C”]
类似于JAVA中的数组。可以使用索引来访问
select xx[0] from table
复杂结构的存储问题,在文件中如何存储?
在创建表的时候,可以定义好各种特殊结构的文本分割符。
示例:
1 | create table user( name string, friends array<string>, children map<string, int>, address struct<street:string, city:string> )row format delimited fields terminated by ',' collection items terminated by '_' map keys terminated by ':' lines terminated by '\n'; |
重点关注几个:
row format delimited fields terminated by
表示一个列的分割符
collection items terminated by
集合中每个选项的分隔符,map ,stuct ,array 都是此分隔符
map keys terminated bymap 中key value的分割符
lines terminated by
一行数据的分割符
通过这些分割符就可以解析出这种复杂结构的数据。后续说明这些数据如何定义
Map stuct array 需要是一个分割符
DDL 操作
默认的hive中只要一个default数据库,我们可以和mysql 一样通过语句创建数据库。
文档地址 https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
注意:hive 中不区分大小写
数据库操作
查看当前数据库
1 | show database; |
创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, …)];
- CREATE DATABASE 表示创建数据库语句
- IF NOT EXISTS 和mysql一样的语法,当不存在的时候创建
- LOCATION hdfs_path 表示可以定义此表的数据存放在hdfs中的目录位置
- WITH DBPROPERTIES 可以为此创建的数据库增加一些key value 自定义属性
创建测试数据库
1 | create databases test_1 |
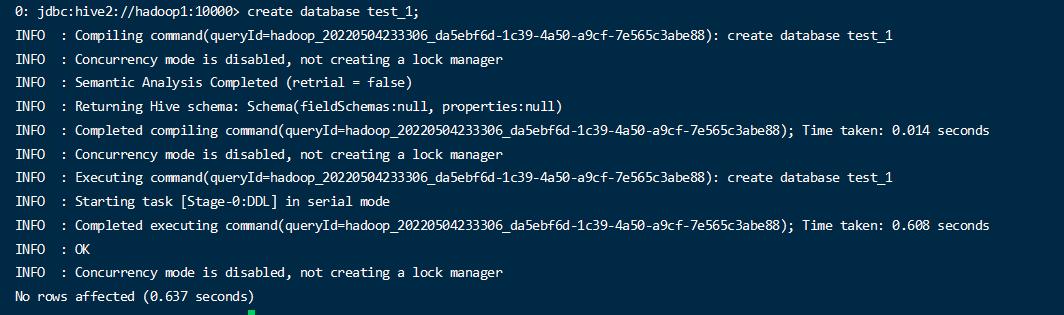
默认的会自动在 /user/hive/warehouse/ 下新建了一个 test_1.db 的文件夹。
在此库下新建的表数据那么应该会在此目录下管理;
创建指定了存储路径的数据库
1 | create database test_2 LOCATION '/hive/test_2'; |
查看数据库的信息
1 | desc database test_1; |

使用 extended 查看详细信息
1 | desc database extended test_1; |
修改数据库的信息
1 | alter database test_1 set dbproperties('a'='b') ; |
删除数据库
1 | drop database if exists test_2; |
删除后,对应的hdfs中的目录也被删除.
数据库中有数据没法直接删除
1 | drop database db_hive cascade; |
强制删除,不推荐,会将不为空的删除.
表操作
创建表语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], …)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], …)]
[CLUSTERED BY (col_name, col_name, …)
[SORTED BY (col_name [ASC|DESC], …)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, …)]
[AS select_statement]
- CREATE TABLE 必须语句,表示创建表操作
- EXTERNAL 表示外部表,在建立表的时候执行一个hdfs的数据路径,此路径的数据是先存在的,hive只能对外部的这个数据做查询操作,删除的时候不能真实删除数据文件,只会删除掉自身的原数据。
- [(col_name data_type)] 表示表的字段和数据类型
- PARTITIONED BY 分区表.
- CLUSTERED BY 分桶表
- SORTED BY 对桶中的一个列或多个列另外排序
- ROW FORMAT 定义列或行的分隔符能格式
- STORED AS 存储成文件的格式,可以选择 SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
- LOCATION :指定表在HDFS上的存储位置。
- AS:后跟查询语句,根据查询结果创建表。
简单创建表
1 | create table if not exists user_info(id BIGINT,name String) comment 'user info'; |
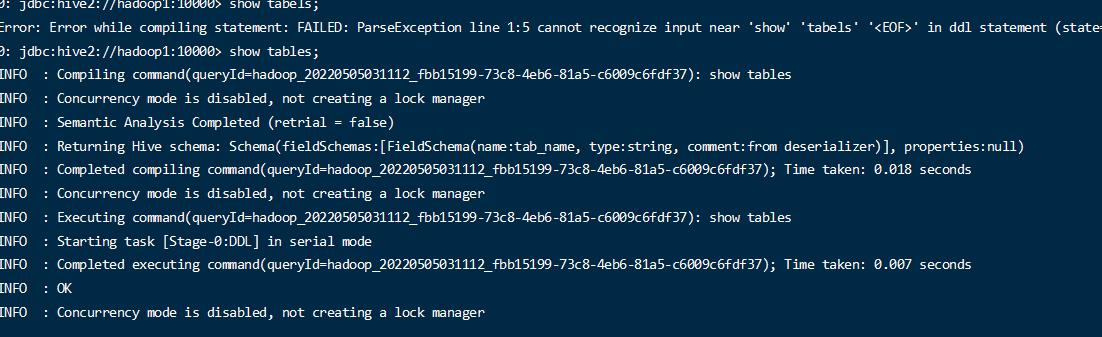
查看表
1 | show tables; |
https://image-1304078208.cos.ap-beijing.myqcloud.com/9a17b4da-d70d-482b-80f3-07e2ef55bc3c.jpg
查看表信息
1 | desc user_info; |
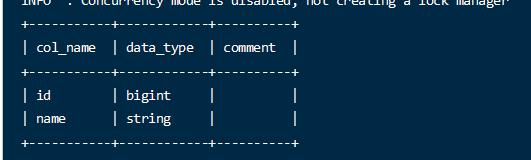
1 | desc extended user_info; |
查看详细的信息

1 | desc formatted user_info; |
格式化显示属性信息

表的重命名
1 | alter table user_info rename TO user_2; |
注意:表明不要创建特殊含义的,比如user 不能 被命名
表结构的变更
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], …)
1 | alter table user_2 add columns (age int comment 'age num'); |
新增一列
REPLACE 是替换表中所有字段结构
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
CHANGE 是更新列的名称。
1 | alter table user_2 change name name_new string; |
改变了列的名称
删除表
1 | drop table user_2; |
外部表
在hive中创建的表,包括我们之前创建的表,默认都是内部表或者称为管理表。hive在维护这些表时同样会去维护表的数据文件。如果在hive中删除一个内部表,那表对应的hdfs文件也会删除。
而外部表表示hive 不真正拥有这些数据。删除这个表只会删除元数据,不过删除表内的数据,hdfs中的部分数据会被删除.在做数据统计的时候,可以通过select + insert 将外部表插入到内部表中。
- 已有用户信息的文件,包含了特殊结构的数据属性。id 名称 喜欢的苹果 城市信息 自定义map属性
1
2
3
41$张三$西瓜,苹果,香蕉$北京,北京$a=10,b=1
2$李四$菠萝,苹果$河北,沧州$c=l
3$王五$苹果$河北,沧州
行分割符 \n
列分隔符 $
集合分隔符 结构,map 分割 ,
map key value 分割 =
- 向文件上传到执行的hdfs目录中
1 | hadoop fs -mkdir /hive/t_user |
- 定义格式创建外部表
1 | create EXTERNAL table t_user(id int,name string,like_fruit array<string> ,address struct<province:string,city:string>,tag map<string,int> ) |
- 查看数据
1 | select * from t_user; |

1 | select like_fruit[0] from t_user; |
根据索引查询数组数据
1 | select address.city from t_user; |
查看对象数据
1 | select tag['a'] from t_user; |
- 查看表的类型
1 | desc formatted t_user; |
- 删除表
1 | drop table t_user; |
可以看到hdfs中的数据还存在;
外部表和内部表的转换。
只需要修改表的属性,就可以完成内部表和外部表的转换
1 | alter table table_name set tblproperties('EXTERNAL'='FALSE'); |
