
hadoop(二)hadoop的安装
hadoop 的安装
hadoop 的运行模式
hadoop 可以根据不同的场景或条件选择不同的运行模式。
单机模式
hadoop 的默认模式。使用本地文件系统,而不是分布式文件系统。
Hadoop不会启动NameNode(名称节点)、DataNode(用于存储数据)JobTracker、TaskTracker等守护进程。Map和Recuce 任务是作为同一个进程的不同部分来执行的。
伪分布式模式
Hadoop的守护进程运行在本机机器上,模拟一个小规模的集群。NameNode DataNode 等都会启动,但是都是在同一个机器上,文件系统也是用的分布式文件系统。和完全分布式的最大区别就是单机或多机器。
完全分布式模式
数据存储和分布到不同的机器上,多台机器并行协作处理数据的计算和存储。
hadoop 安装
这里选中完全分布式模式来安装hadoop。
机器环境准备
机器准备
1 | 192.168.199.120 hadoop1 |
关闭防火墙
1 | systemctl stop firewalld |
配置安装阿里云或其他加速镜像源
1 | sudo mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup |
//查看当前的列表
1 | sudo yum repolist |
安装必要依赖
1 | yum install -y epel-release |
设置主机名和修改host文件
主要为了方便后续的操作
120执行
1 | hostnamectl set-hostname hadoop1 |
121执行
1 | hostnamectl set-hostname hadoop2 |
122执行
1 | hostnamectl set-hostname hadoop3 |
3台机器同时修改host文件ip映射
1 | cat >> /etc/hosts << EOF |
使用命令: cat /etc/hosts 查看写入成功结果
创建操作用户
3台机器都要创建
1 | //新增用户hadoop |
制作文件分发脚本
linux sync 命令,可以方便的将当前机器上的数据发送到指定的机器,为了更好的处理数据同步问题,对sync使用脚本进一步封装,可以更加简单的处理数据的在集群环境中的同步。
切换到 普通用户 hadoop
创建当前用户bin目录
1 | mkdir -p ~/bin |
写入脚本文件
1 | vim xsync |
1 | #!/bin/bash |
此脚本主要是将某个文件或目录同步创建到其他机器上的相同位置。
脚本文件中的机器名称 可根据实际情况进行修改
添加执行权限并拷贝到 /bin 目录
1 | chmod +x xsync |
将脚本分发到其他机器,其他机器也就能直接使用此脚本了。
1 | sudo xsync /bin/xsync |
配置ssh免登录
ssh 命令
1 | ssh ip 登录访问远程机器 |
默认机器之间ssh登录需要输入密码,可以通过相互配置公钥的方式实现免密码登录。
A 机器生成公钥和私钥,使用私钥加密的数据可以通过公钥解密,A将公钥发给B机器,B机器可以通过公钥解析A的数据,A将可以不输入密码的方式访问B。
生成 公钥和私钥对
1 | ssh-keygen -t rsa |
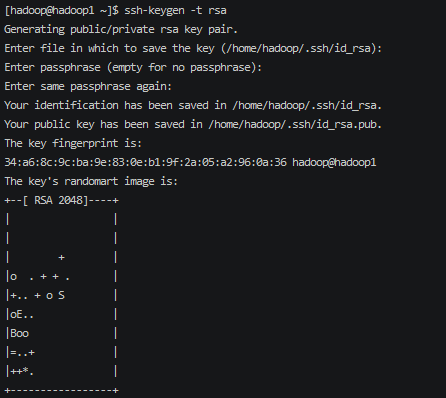
生成信息将在 ~/.ssh 目录下 ll -a 查看隐藏目录
1 | rw-------. 1 hadoop hadoop 1679 4月 9 11:47 id_rsa |
执行命令公钥分发(每个机器都要执行)
1 | ssh-copy-id hadoop1 |
注意: ssh 只是针对当前的登录用户的,如果切换其他用户是无法免登录的
切换成root用户,来配置免密码登录
1 | su root |
同样需要重新生成公钥和秘钥,因为不同的用户的秘钥信息都是独立的。
安装JAVA
hadoop 依赖java运行环境,所以必须安装java.
在hadoop1 机器上执行操作。
1 | sudo mkdir -p /usr/local/software/jdk |
下载jdk
https://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.html
下载后上传至服务器。
注意此版本使用jdk8.不要使用太高的版本,不然可能出现运行错误
解压
1 | sudo tar -zxvf jdk-8u311-linux-x64.tar.gz -C jdk |
配置环境变量
1 | cd /etc/profile.d/ |
内容:
1 | #JAVA |
1 | source /etc/profile |
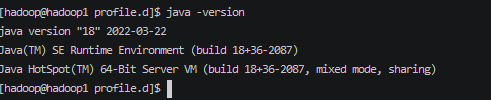
安装成功。
向其他机器分发jdk
1 | //创建目录 |
向其他机器分发环境变量
1 | sudo xsync /etc/profile.d/my_env.sh |
其他机器执行java -version 验证是否成功
1 | source /etc/profile |
安装HADOOP
选择合适的hadoop版本
https://archive.apache.org/dist/hadoop/common/
这里选用3.1.3
1 | https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz |
在hadoop1 机器上 下载hadoop,安装完成后分发到其他机器.
1 | cd /usr/local/software |
解压
1 | mkdir /usr/local/software/hadoop |
可以看到目前的hadoop的目录结构
配置环境变量,编辑文件
1 | sudo vim /etc/profile.d/my_env.sh |
1 | #hadoop |
查看版本验证是否成功
1 | source /etc/profile |
单机安装完成,接着向其他机器分发文件
1 | xsync /usr/local/software/hadoop |
其他机器验证安装
1 | source /etc/profile |
至此3台机器都已经安装成功。
集群规划和配置
首先规划组件在机器上的分布
| hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
NameNode SecondaryNameNode 不要在同一个机器上,考虑到数据的安全
ResourceManager 也尽量单独一个机器
hadoop的自定义配置文件放在
HADOOP_HOME/etc/hadoop 目录下
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
这4个配置文件分别对应着4个组件相关的自定义配置。
hadoop运行时 会根据自己所在jar包内的默认配置 + 自定义配置 应用于最终配置。
完成 HDFS 和YARN的2个配置
修改core-site.xml
在config configuration 下定义配置信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9820</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/software/hadoop/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop_user</value>
</property>
<!-- 配置该用户允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.hadoop_user.hosts</name>
<value>*</value>
</property>
<!-- 配置该用户允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.hadoop_user.groups</name>
<value>*</value>
</property>- fs.defaultFS 配置nameNode的地址和端口号
- hadoop.tmp.dir 配置hdfs 在磁盘的存储路径
修改hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:9868</value>
</property>
- 主要用来定义namenode 和 secondaryNameNode 的 地址和端口号
修改 yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!---配置日志聚集服务器-->
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop1:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>- 配置 yarn.resourcemanager.hostname
- 和配置yarn对资源的控制信息
- 配置日志聚合功能,将日志统一放到某个节点的目录下
修改 vim mapred-site.xml
mapreduce.framework.name yarn <!-- 配置历史记录服务器,如果不配置。历史的操作将不会保留 --> <!-- 历史服务器端地址 -->mapreduce.jobhistory.address hadoop1:10020 mapreduce.jobhistory.webapp.address hadoop1:19888 - 配置历史服务器配置,如果不配置历史的mapr操作将不会被记录,所以需要配置
- 修改mr在yarn 上运行
配置修改完毕后,同步到其他节点
1 | xsync /usr/local/software/hadoop/hadoop-3.1.3/etc |
集群启动
启动前的准备
配置workers文件,通过worker文件,集群能够互相知道其他节点的存在.
1 | vim /usr/local/software/hadoop/hadoop-3.1.3/etc/workers |
1 | hadoop1 |
注意: workers 文件不要有空格
配置分发
1 | xsync /usr/local/software/hadoop/hadoop-3.1.3/etc |
第一次启动 – 初始化操作
集群的第一次启动的时候,nameNode需要做初始化的操作。
在nameNode所在的节点,hadoop1 上操作
1 | hdfs namenode -format |
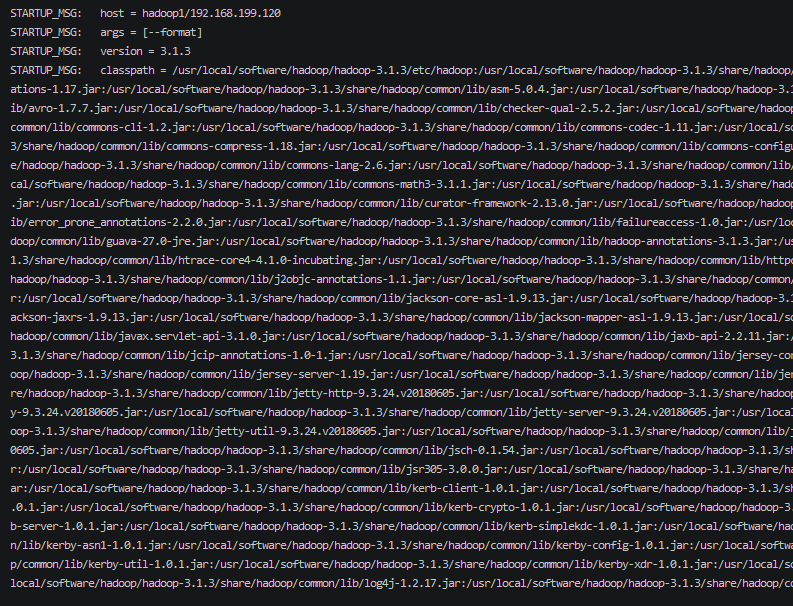
如果这里有错误信息就需要检查是否配置文件有问题了。
如果要对当前集群重置操作,需要将logs data 目录删除,停止所有服务后重新执行此初始化操作
还要删除 /tmp 目录下生成的文件,不然无法重新格式化
注意: 可能出现初始化失败的情况,
启动
启动dfs
nameNode 所在节点启动 hadoop1
1 | sbin/start-dfs.sh |
启动yarn
ResourceManager 所在节点启动 hadoop2
1 | sbin/start-yarn.sh |

启动历史服务器
在配置的hadoop1的机器上启动
1 | mapred --daemon start historyserver |
至此。hdfs 和yarn 就启动起来了;
前面配置的web访问地址也可以访问了;
hdfs 访问
NameNode 所在节点IP访问
http://hadoop1:9870

Yarn 访问
当然这个端口号是默认端口,也可以自定义配置。默认配置可以查看hadoop 的jar包
\share\hadoop\yarn\yarn-default.xml 中查看
历史服务器的web访问
http://hadoop1:19888/jobhistory
日志的集中访问,通过
服务中的各个组件可以分别进行启动或停止;
1 | hdfs --daemon start/stop namenode/datanode/secondarynamenode |
为了更好的管理集群,可以通过编写脚本进行统一的控制
在hadoop1 机器上
查看所有jpa的脚本
1 | vim ~/bin/jpsall |
1 | #!/bin/bash |
1 | chmod +x ~/bin/jpsall |
hadoop 启动和停止脚本
1 | vim ~/bin/hadoop_manager |
1 |
|
1 | chmod +x ~/bin/hadoop_manager |
1 | 启动服务 |
测试服务
hdfs 测试
hdfs dfs 查看可以执行的客户端操作
-cp 拷贝
-mkdir 创建目录
-put 上传操作
….等等很多操作
创建文件夹
1 | hdfs dfs -mkdir /test_data |
从管理页面也可以看到新增的目录或文件
上传文件到指定目录
1 | hdfs dfs -put hadoop-3.1.3.tar.gz /test_data |
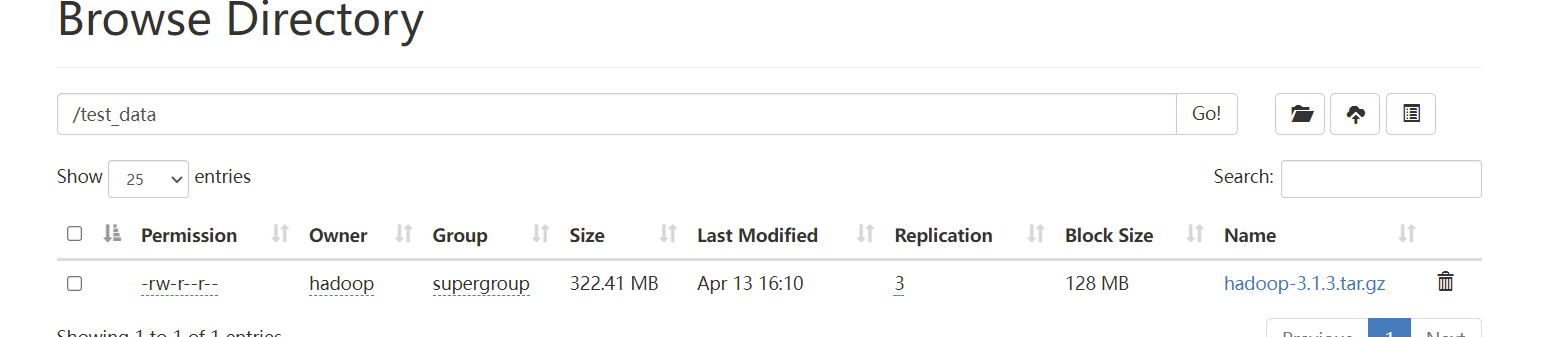
- 上传文件后可以查看目录,文件存储在了 data目录下的 /data/dfs/data/current/BP-1406509639-192.168.1.103-1649830935852/current/finalized/subdir0/subdir0
- 数据是分块存储的,默认的块大小是128M(可以自行更改配置)
MapReduce 测试
/share/hadoop/mapreduce/ 下提供了一些示例的mapreduce jar包。
以workcount测试为例;
新建一个文件
1 | vim ~/hadoop/input/workcount.txt |
1 | Love |
将此文件上传到hdfs
1 | hdfs dfs -mkdir /input |
通过自带的示例执行此文件
1 | hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output |
注意: 输出到一个不存在的目录,不然不报目录已经存在.
将执行hdfs /input 目录下的文件, 结果输出到 /output 中
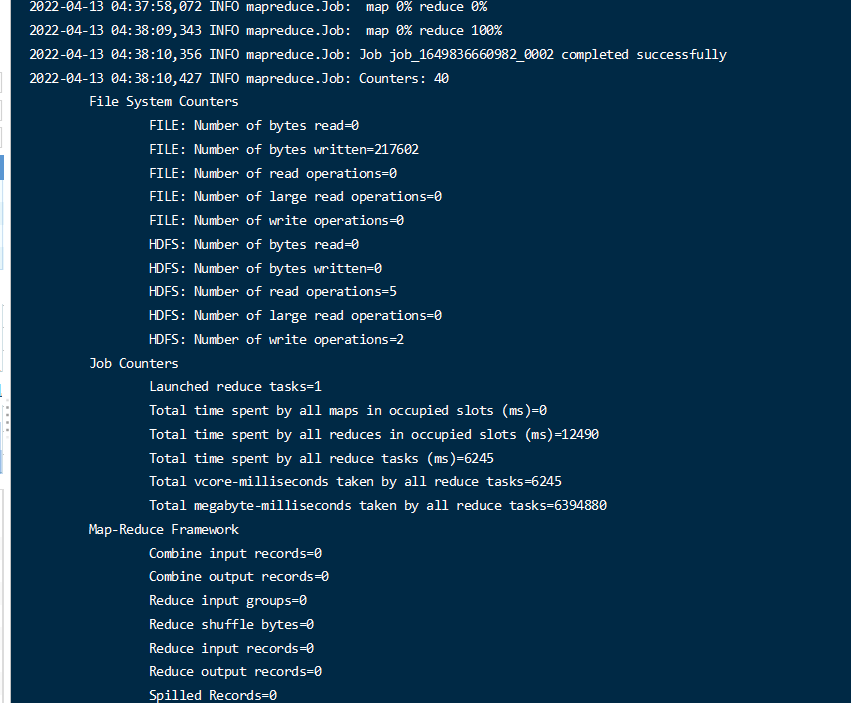
最终会生成2个文件。
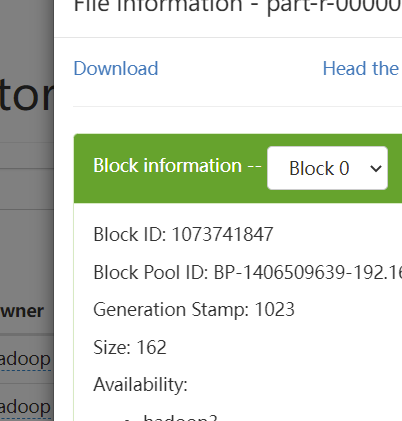
下载数据文件获取生成的结果
1 | Love 3 |
