
hadoop(一)hadoop基本介绍和说明
hadoop 基本介绍
hadoop 是什么
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
主要解决,海量的数据存储和海量的数据的分析计算。
hadoop 有时候并不是指的某一项技术,而是一个hadoop生态圈。
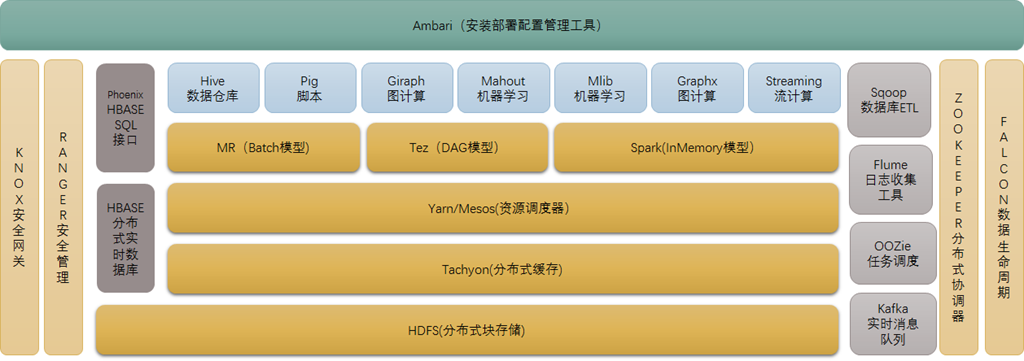
包含了多种解决大数据问题的组件和框架。
hadoop 官网 https://hadoop.apache.org/
大数据相关组件简介
Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统;
Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等
hadoop 的组成
hadoop 的核心功能在于对大数据的存储和计算。在hadoop内部有三个重要的组件组成
HDFS
大数据量的存储
MapReduce
分布式数据计算
Yarn
计算资源调度,合理计算每个节点根据计算量分配系统资源。
hadoop 的版本和组件说明
hadoop 发展到目前共有3个大版本,分别是 1.x ,2.x 3.x
1.x 的组件组成有 common + HDFS+ MapReduce
2.x 的组件组成有 common+ HDFS+ MapReduce+ Rarn
3.x 和2.x 在组件组成上并没有什么明显的变化。
hadoop 在2.x 和1.x 最大的区别在于将用于资源调度的功能从1.x 的MapReduce 中抽离出来而让新增的Yarn来管理。
HDFS简介
HDFS(Hadoop Distributed File System)是hadoop生态系统的一个重要组成部分,是hadoop中的的存储组件。
hdfs 中有3个重要的组件
NameNode (nn)
存储文件的元数据,比如文件名,文件大小,文件的结构信息,每个文件的块列表和块在的dataNode信息。可以理解为是文件的目录或索引。通过NameNode 可以快读获取文件的相关的位置或信息
SecondDary NameNode(2nn): 定期对NameNode 数据备份。可以看做NameNode 的副本,防止NameNode 所在机器挂掉,导致服务不可用。
DataNode(nn): 在本地文件系统存储文件块数据,以及块数据的校验和。
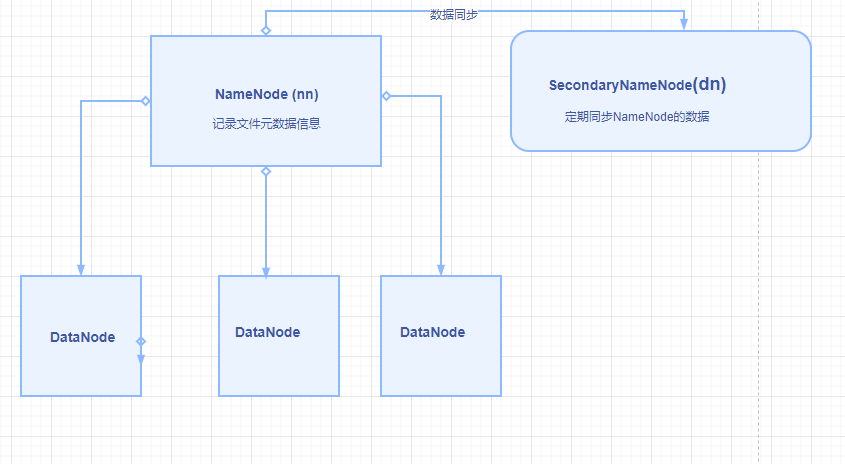
三个组件的关系图
MapReduce简介
MapReduce是一种用于数据处理的编程模型 。
MapReduce 分为2个阶段处理数据。
Map 阶段
在多个机器上并行分布式处理各自机器负责的运算数据。
Reduce 阶段
由一台机器将map阶段由多台机器计算的结果进行汇总返回。
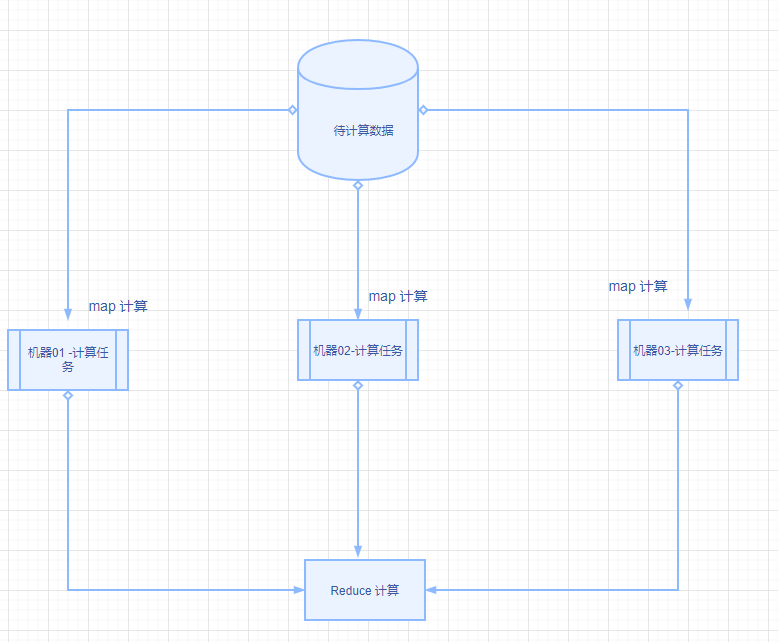
MapReduce 基本计算过程
YARN简介
Apache Yarn(Yet Another Resource Negotiator的缩写)是hadoop集群资源管理器系统,Yarn从hadoop 2引入,最初是为了改善MapReduce的实现,但是它具有通用性,同样执行其他分布式计算模式。
Yarn从整体上是属于master/slave模型,主要依赖于三个组件来实现功能,第一个就是ResourceManager,是集群资源的仲裁者,它包括两部分:一个是可插拔式的调度Scheduler,一个是ApplicationManager,用于管理集群中的用户作业。第二个是每个节点上的NodeManager,管理该节点上的用户作业和工作流,也会不断发送自己Container使用情况给ResourceManager。第三个组件是ApplicationMaster,用户作业生命周期的管理者它的主要功能就是向ResourceManager(全局的)申请计算资源(Containers)并且和NodeManager交互来执行和监控具体的task。
ResourceManager (RM)
主要作用:
- 处理客户端的请求
- 监控NodeManager
- 启动和监控ApplicationMaster
- 资源的分配和调度
NodeManager (NM)
主要作用:
- 管理单个节点上的资源
- 处理ResourceMnager 的命令
- 处理ApplicationMaster的命令
ApplicationMaster (AM)
主要作用:
- 负责数据的切分
- 为应用程序申请资源并分配给内部的任务
- 任务的监控与容错
Container
主要作用:
资源的抽象,封装了节点上的资源信息,CPU,磁盘,网络等。
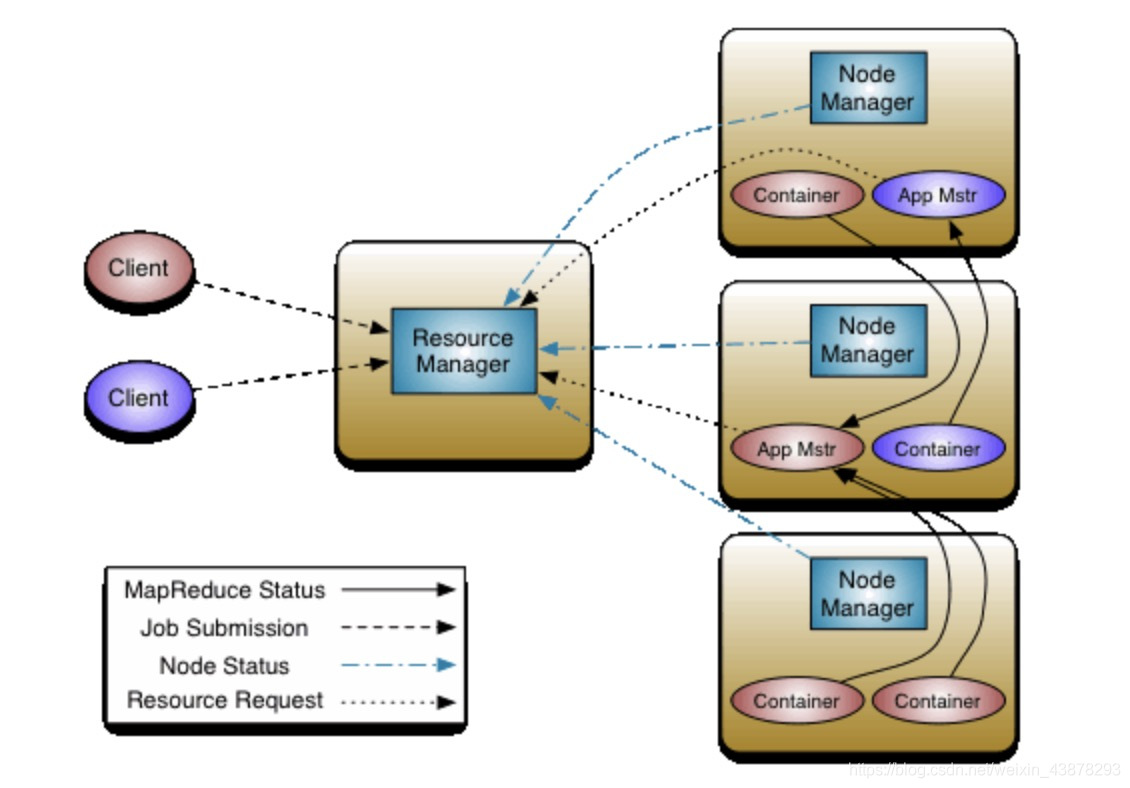
yarn 结构图
yarn基本的执行流程是:
- 客户端向ResourceManger 提交任务相关的资源信息.
- ResourceManger 响应请求,进行权限检查,通过后,提交任务到等待队列,等待调度。
- 当有资源可用时,ResourceManger 选择一个NodeManger,并请求NodeManger启动一个container来运行该任务的ApplicationMager
- ApplicationMaster 向 ResourceManager 请求运行任务所需的资源
- 调度器 Scheduler 响应 ApplicationMaster 的资源请求,并根据资源调度策略分配资源,返回资源信息给ApplicationMaster
- ApplicationMaster 根据调度器返回的资源信息,协商对应 NodeManager 启动 container,以便在 container 中运行任务
- ApplicationMaster 调度任务运行,并监控任务运行的状态(由 container 和 ApplicationMaster 的心跳通信完成),定时向 ResourceManager 汇报任务的状态信息。
- ApplicationMaster 调度任务运行完毕,释放 container 资源。
