
hadoop(三)hadoop组件之HDFS-HDFS认识和说明
HDFS认识和介绍
概述
HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统,是一种旨在在商品硬件上运行的分布式文件系统。它与现有的分布式文件系统有许多相似之处。但是,与其他分布式文件系统的区别很明显。HDFS具有高度的容错能力,旨在部署在低成本硬件上。
一句话总结:就是一个支持分布式大数据量存储的文件系统。
适用场景: 适合读多写少不修改的场景。(不支持文件的修改)
优点和缺点
优点
容错性
支持多副本保存文件
大数据量
支持TB,PB级别的数据量
支持百万以上的文件数量
低成本
对机器的要求不高
缺点
访问数据比较慢
无法高效的对大量小文件存储
hdfs的设计架构通过nameNode 存储文件目录信息,如果存储大量的小文件,将会让NameNode的数据量剧增,造成查找文件的时间变长,寻址时间会超过读取文件时间
不支持并发写入,文件修改
同一个文件只能一个写入操作。
数据不能修改,只能对数据在末尾追加操作。
HDFS 架构
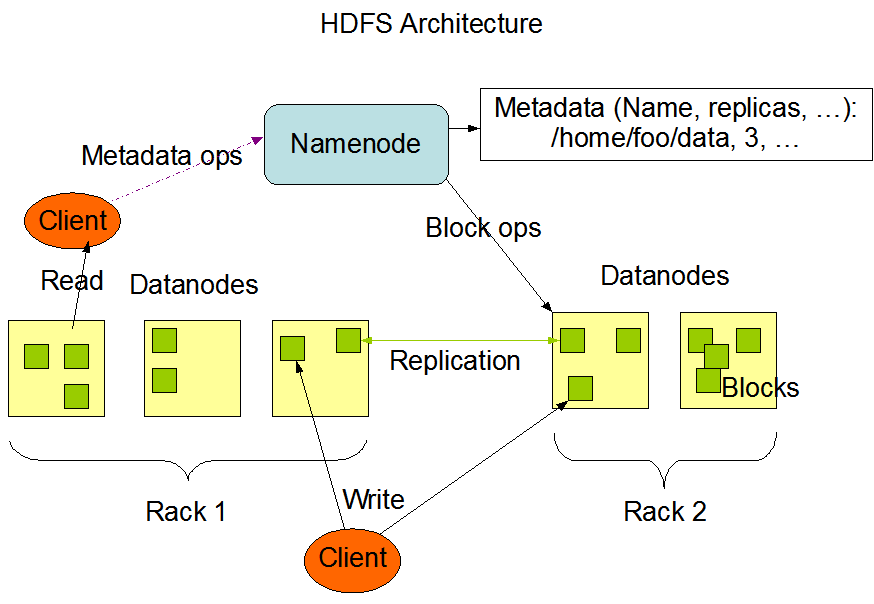
HDFS中的角色
Client 客户端操作读写操作
Client 可以对文件执行读写操作,也可以访问NameNode 获取文件元信息
文件上传的时候,Client 将文件进行切分成一个一个的Block然后进行上传。
NameNode 存储文件的元数据信息,名称,地址等
DataNode 数据节点 ,存储文件数据 内部由一个一个的Blocks组成
Secondary NameNode
分担NameNode工作量,定期合并Fsimage和Edits,并推送给NameNode
紧急情况下,帮助恢复NameNode
在NameNode挂了的情况下,Secondary NameNode 并不会切换成NameNode
hdfs 写入数据流程
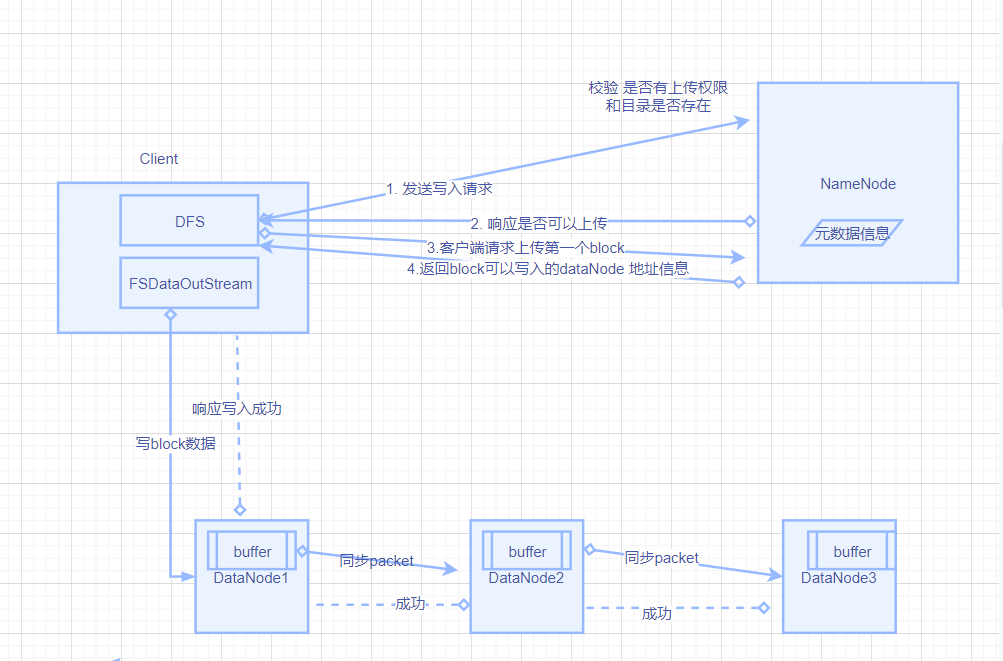
- 客户端请求NameNode 请求是否可以执行上传请求
- NameNode 做权限校验和目录是否存在等操作 然后响应客户端是否可以执行上传
- 客户端对文件进行切块,首先请求第一个block信息
- NameNode 根据副本数等信息,返回block 要写入的DataNode信息,假如返回的是 n1 n2 n3
- 客户端 使用FsDataOutPutStream 模块 将流写入一个DataNode上,比如写入n1 ,n1 在收到数据会依次向后续其他需要写入的节点传递数据。
- 所有写入节点逐级应答客户端
- 客户端向n1写入一个block数据,先从磁盘读取数据到一个本地内存缓存,以packet为单位,每个节点只要获取到一个packet就传递到下一个节点。
并不是第一个节点接收完数据后才向下一个节点传递的,可以近似的理解为是一个多个节点一起同步的过程。 - 当第一个block写完后,接着再请求第二个block的请求操作。循环直到写完所有的block
hdfs 读取数据流程
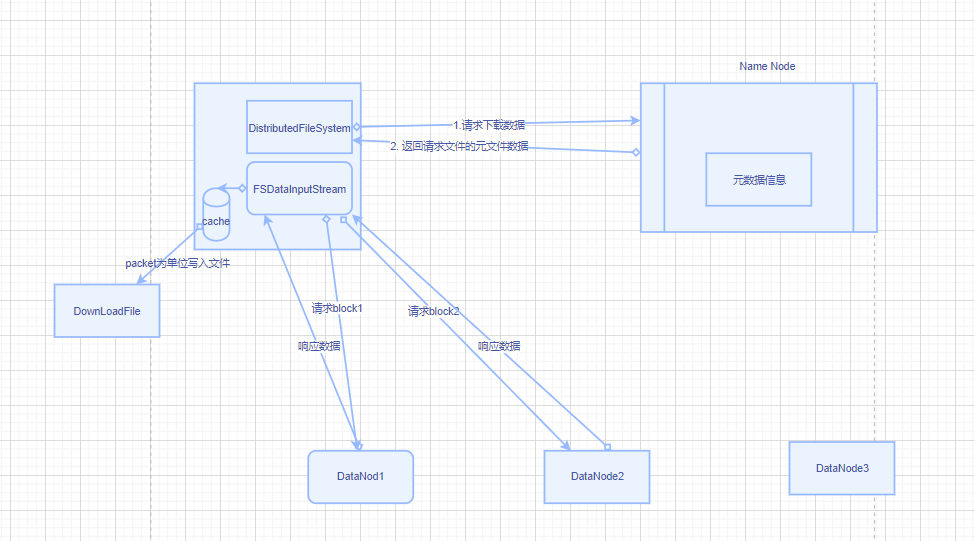
- 客户端请求NameNode执行下载请求,NameNode 获取到文件所在的文件块的地址返回。
- 挑选一台DataNode(就近原则,然后随机)服务器,获取数据。
- DataNode 传输数据给客户端,从磁盘中以packet为单位读取和检验
- 客户端以packet为单位接收数据,先在本地缓存数据,然后写入目录文件
注意读取 请求 Block1 和block2 是串行执行的,即使不在同一个节点上也是执行完一个再执行另一个
块的大小
默认的块的大小是 128M. 可以通过dfs.blocksize 来设置.
一般机械硬盘设置为128M,固态硬盘设置为256M 即可。
设置太小,会增加寻址时间,设置太大,会增加数据传输,因为请求到块上,需要处理块的数据。
