
hadoop(六)hadoop组件之HDFS-HDFS常用配置和故障恢复
常用配置项
CheckPoint 配置
SecondaryNameNode每隔一小时执行一次
修改[hdfs-default.xml] 更改配置
1 | <property> |
一分钟检查一次edit 文件 操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
1 | <property> |
DataNode 不可用参数设置
默认情况下当DataNode 超过 10分钟 + 30秒未发送心跳,将认为服务不可用了。
超时时间 = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
可以修改 hdfs-site.xml 的配置
1 | <property> |
NameNode 故障恢复
NameNode数据故障后,可以从SecondaryNameNode 将数据恢复到NameNode中;
- 故障操作
杀死NameNode 同时清理掉NameNode数据1
2
3
4jps 获取进程
kill -9 9753 杀死NameNode进程
rm -rf $Hadoop_HOME/data/dfs/name/* 删除name的数据
可以看到目前已经不能执行相关的操作了。

拷贝2nn 中的 name相关数据到 nn 中的节点目录下
在nn所在节点操作
1 | scp -r hadoop@hadoop3:/usr/local/software/hadoop/hadoop-3.1.3/data/dfs/namesecondary/* /usr/local/software/hadoop/hadoop-3.1.3/data/dfs/name |
执行完毕后,数据已经拷贝回来了
接着启动NameNode
1 | hdfs --daemon start namenode |
可以看到NameNode 已经启动,并且数据也都还在。
加入新节点
当需要对当前集群增加机器的时候;
新增一台机器。关闭防火墙,设置hostname,创建普通用户
安装java
安装hadoop
同步所有的host 文件,host文件中新增新的节点信息,所有节点同步
1 | 192.168.xx.xx hadoop4 |
- 节点之前互相配置ssh免登录
生成秘钥
1 | ssh-keygen -t rsa |
1 | ssh-copy-id hadoop4 |
- 修改所有的 etc/works 文件增加新的节点信息
增加 hadoop4
- 在新节点上启动DataNode 和 NodeManger
这里是否要单独启动,取决于是此机器节点是否添加到works文件中,如果works文件中已经添加了,是不用单独的控制启动或关闭的。
1 | hdfs --daemon start datanode |
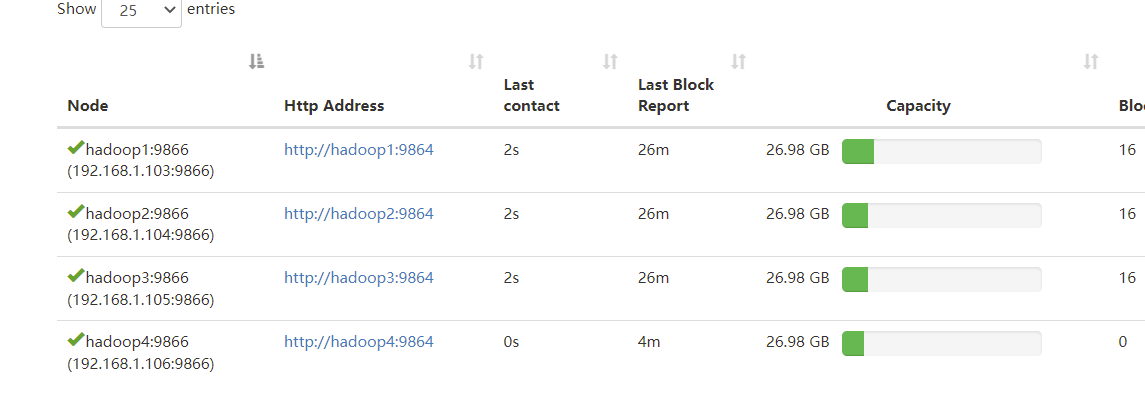
可以查看DataNodes 看到新节点已经加入进来了;
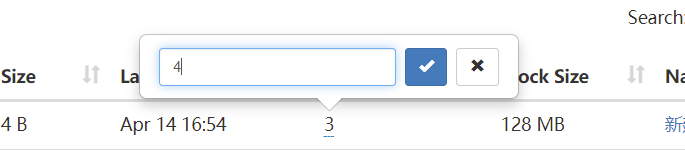
改变一个文件的副本数,由3改成4;
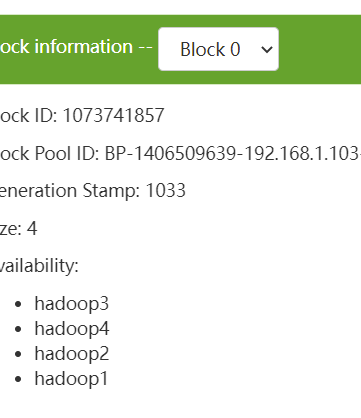
可以看到数据分布已经可以再新的节点上了
可以使用此命令均衡数据。
1 | ./start-balancer.sh |
退出旧节点
通过黑白名单机制使节点优雅的退出集群。
添加到白名单的主机节点,都允许访问NameNode,不在白名单的主机节点,都会被退出。添加到黑名单的主机节点,不允许访问NameNode,会在数据迁移后退出。
实际情况下,白名单用于确定允许访问NameNode的DataNode节点,内容配置一般与workers文件内容一致。 黑名单用于在集群运行过程中退役DataNode节点。
- 所有Node节点下的 etc/hadoop 目录下创建 whitelist 和 blacklist 文件.
whitelist 内容
1 | hadoop1 |
- 在hdfs-site.xml配置文件中增加dfs.hosts和 dfs.hosts.exclude配置参数
配置黑白名单文件路径
vim hdfs-site.xml
1 | <!-- 白名单 --> |
文件同步到所有节点,同时重启集群
当启用了黑白名单管理后,可以利用黑名单来退出不服役的节点;
配置 blacklist 文件
vim blacklist
1 | hadoop4 |
编辑后同步所有节点。
- 刷新NameNode、刷新ResourceManager
1 | hdfs dfsadmin -refreshNodes |
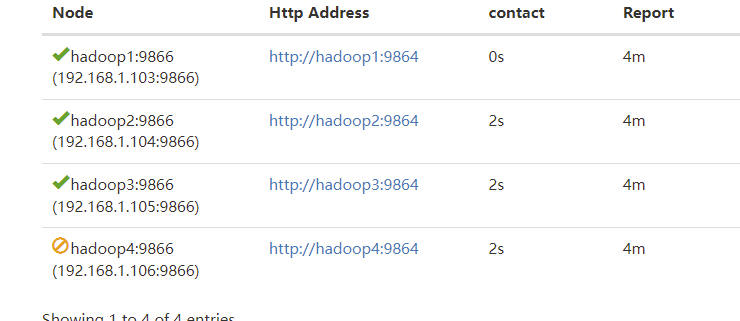
可以看到节点状态已经变化;
节点状态变为 Decommissioned 后
就可以将节点停止掉
1 | hdfs --daemon stop datanode |
同时从白名单中删除.
注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役
数据不均匀,使用命令 数据再平衡
1 | sbin/start-balancer.sh |
