
hadoop(七)hadoop组件之MapReduce-MapReduce基本介绍和认识
MapReduce
简介
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)”和”Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并行运行在一个Hadoop集群上。
简单的说就是 MapReduce 是一种先分再合的一种计算思想,框架已经将此工作模式定义好了,我们需要实现业务逻辑的那部分,就可以使用框架的这种计算方式得到计算结果。
优缺点
优点
易于编程
只需要按照它得规范实现接口,实现逻辑即可,就可以完成分布式计算的任务。不用考虑分布式计算的问题。
良好的拓展性
可以通过增加机器节点拓展计算能力
高容错性
一台机器挂了,它会自动将计算任务转移到其他的机器节点上执行,不会因为一个任务计算失败而失败。
缺点
不擅长实时计算
一般计算时间比较久,适合大数据量的计算,而不是实时的。追求的是量而不是速度。
不擅长流式计算
计算的数据集或文件比如是静态的,不能动态变化。 (流式计算使用 flink)
不擅长DAG(有向无环图)计算
DAG计算 一般是让前一个任务的输出结果作为下一个任务的输入。MapReduce做此种计算的时候,需要将每个MapReduce 的输出结果都写入到磁盘上,造成大量磁盘IO,影响性能,不推荐使用。
MapReduce 思想
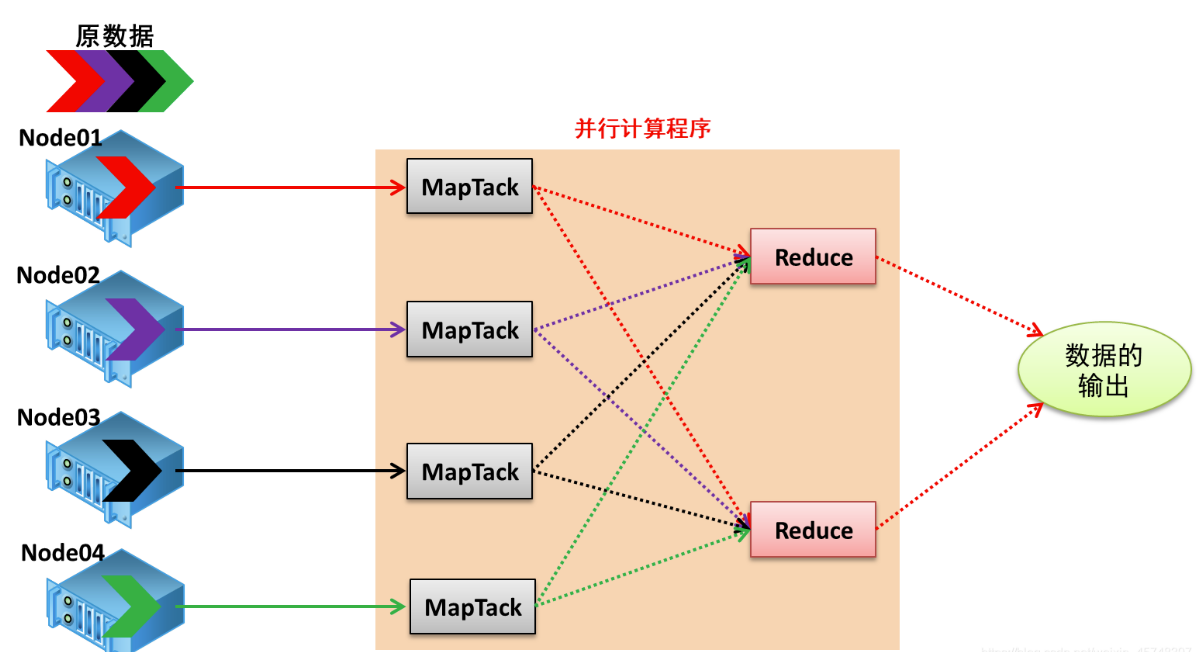
MapReduce 是一种先分后合的一种思想。
分为2个阶段,Map 节点和Reduce 阶段。
Map 阶段 map阶段会有多个MapTask 任务实例,并发执行。相互之间处理的数据不重叠,互相不相干。相当于每个任务分担一部分处理任务。
Reduce 阶段 map 阶段运行的多个MapTask都会生成一个独立的输出结果,但是这个结果并非最终的单一结果,reduce阶段就是将这些一小块 一小块的 小结果,合并成一个大结果。
以为在map阶段已经完成了大部分的计算任务,reduce 主要将数据合并计算就完成最终的结果输出。
MapReduce 中的进程
MapReduce 的一个任务执行过程中有三类进程
MrAppMaster
负责整个程序的过程调度和状态协调,相当于是此程序任务的领导和控制者。如果某个任务因为意外挂掉也是由它来决策如果处理,是否要在其他节点重新运行task.
MapTask
负责map的任务处理。
ReduceTask
负责reduce的任务处理。
MapReduce 的开发步骤
编程的程序主要编写3个部分
Mapper
写自己的业务类继承于 org.apache.hadoop.mapreduce.Mapper 类 ,处理map计算逻辑。
Mapper 类是个泛型方法需要指定输入 输出的 Key value 泛型。
业务相关的逻辑写到map() 方法中,map() 方法会被循环调用。
Mapper 中的方法
setup 只会执行一次
map 每个key value执行都会执行一次
run 执行一次运行方法
cleanup 结束会执行一次Reducer
写自定义Reducer 业务类继承于 org.apache.hadoop.mapreduce.Reducer ,处理 Reducer 合并计算逻辑
写自定义Reducer 类是个泛型方法需要指定输入 输出的 Key value 泛型。
Reducer 相关逻辑写到reduce 方法中,reduce 方法调用的次数跟 相同的key的组有关,有几组就调用几次。
Reducer 中的方法
reduce 每个key都会调用一次
run 执行一次运行方法
setup 只会执行一次Driver
相当于是yarn集群的客户端,提交任务的相关的信息给yarn.
MapReduce 中有自己的一套数组类型类,指定输入输出的时候需要使用这些类来表示类型。
类型说明:
BooleanWriable:标准布尔型数
ByteWriable:单字节数
DoubleWriable:双字节数值
FloatWriable:浮点数
IntWriable:整型数
LongWriable:长整型数
Text:使用UTF8格式存储的文本
NullWriable:当<key,value>中的key或value为空时使用
可以注意到很多类型名称都有Wriable 后缀,表示的是可以序列化的。后面会说到.
