
shardingjdbc(九)数据源分离
读写分离是比较常见的应用场景,读库负责写入操作,多个从库通过binlog日志同步主库的写操作。读操作都落到读库上,写操作落到写库上;
基本使用
shardingjdbc 也支持读写分离的功能,同时也支持读操作的负载均衡算法;
这里有3个数据源;
db1 db2 db3
db1 是写库。db2 和db3 是读库;
每个库中都一个相同的表
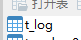
首先配置3个数据源
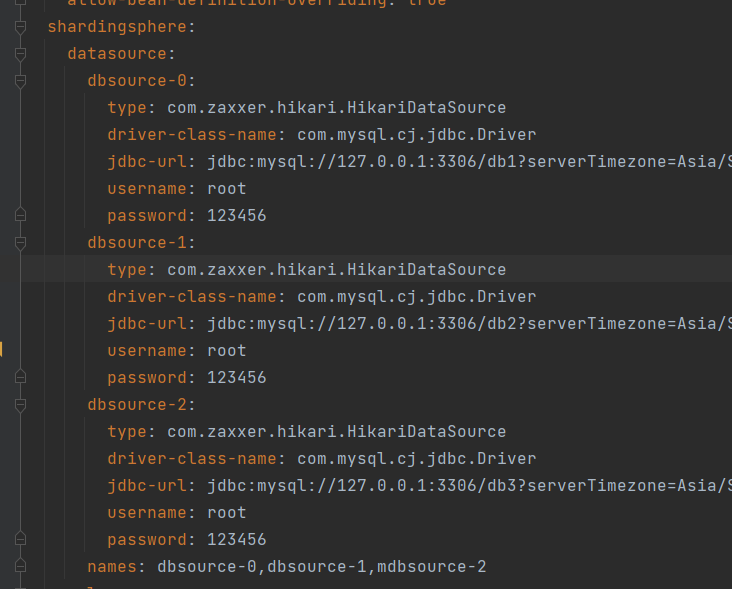
配置那些库是写库,那些库是读库。
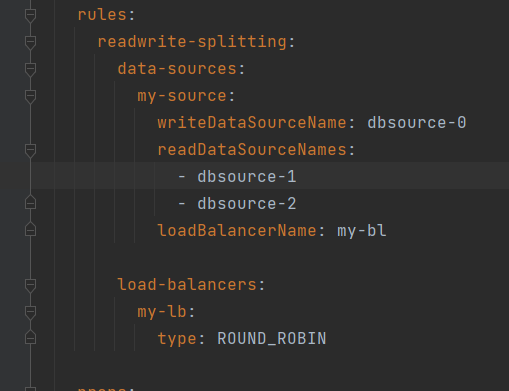
这样配置表示写操作到source-0 读操作从source-1 和source-2 使用轮询算法;
- 验证
执行一个插入操作,通过sql能看到只插入到第一个数据源;
而执行查询操作则是从剩下的2个数据源中轮询执行;
- 注意在配置数据分片的 actual-data-nodes 的时候的数据源名称就可以使用读写分离定义的名称
如上图的 my-source
具体配置可参考官网 (注意版本) : 读写分离 :: ShardingSphere
负载算法
在多个数据源中负载切换内置了2种算法,分别是轮询和随机,可以根据需求配置
轮询算法 类型:ROUND_ROBIN
随机访问算法 类型:RANDOM
自定义负载算法
负载均衡的接口类是
1 | public interface ReplicaLoadBalanceAlgorithm extends ShardingSphereAlgorithm, RequiredSPI { |
这个接口也是支持通过SPI机制来拓展自定义的负载均衡算法的;
基本自定义方法
实现 ReplicaLoadBalanceAlgorithm 类
定义spi文件,写具体实现类
写负载均衡实现 getDataSource 方法;
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Related Articles

Comment
