
hbase(六)hbase整合phoenix和索引
整合Phoenix
什么是Phoenix
现有hbase的查询工具有很多如:Hive,Tez,Impala,Shark/Spark,Phoenix等。今天主要说Phoenix。phoenix是一个在hbase上面实现的基于hadoop的OLTP技术,具有低延迟、事务性、可使用sql、提供jdbc接口的特点。 而且phoenix还提供了hbase二级索引的解决方案,丰富了hbase查询的多样性,继承了hbase海量数据快速随机查询的特点。但是在生产环境中,不可以用在OLTP中。在线事务处理的环境中,需要低延迟,而Phoenix在查询HBase时,虽然做了一些优化,但延迟还是不小。所以依然是用在OLAT中,再将结果返回存储下来。
Phoenix完全使用Java编写,作为HBase内嵌的JDBC驱动。Phoenix查询引擎会将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准的JDBC结果集。直接使用HBase API、协同处理器与自定义过滤器,对于简单查询来说,其性能量级是毫秒,对于百万级别的行数来说,其性能量级是秒。
简单的说hbase直接使用是比较麻烦的,可以像hadoop 可以使用hive简化hadoop的操作一样,对于hbase可以使用phoenix 简化hbase的相关api操作。
而且Phoenix 是可以通过标准的jdbc操作来操作hbase的数据。
Phoenix 官网 https://phoenix.apache.org/
安装
因为hbase使用的2.4版本,所以 下载这个文件
- 将文件上传到服务器,并且解压操作。
1 | tar -zxvf phoenix-hbase-2.4.0-5.1.2-bin.tar.gz |
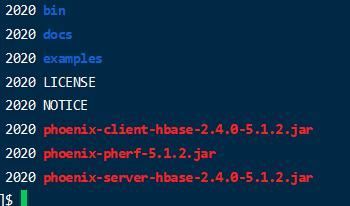
得到这么几个文件
- 主要使用的是这3个jar 包,将 phoenix-server-hbase-2.4.0-5.1.2.jar 复制到 hbase 的lib 目录下,并且每个节点都需要复制。
1 | cp phoenix-server-hbase-2.4.0-5.1.2.jar /usr/local/software/hbase/hbase-2.4.0/lib |
- 重启hbase服务
1 | ./stop-hbase.sh |
- 配置phoenix 环境变量

1 | source /etc/profile |
- 使用客户端连接
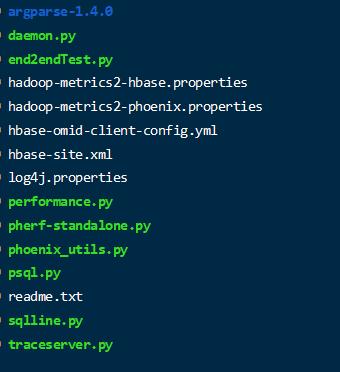
可以看到 phoenix 的bin 目录下又需要可指定的工具程序。
使用 sqlline.py 程序来连接hbase
1 | sqlline.py hadoop1,hadoop2,hadoop3:2181 |
注意:连接信息里只有最后一个加端口号,前面2个不加。

phoenix Shell 基本操作
相关语法查询 https://phoenix.apache.org/language/index.html
- 展示所有的表,相当于 mysql 的show tables
1 | !tables |
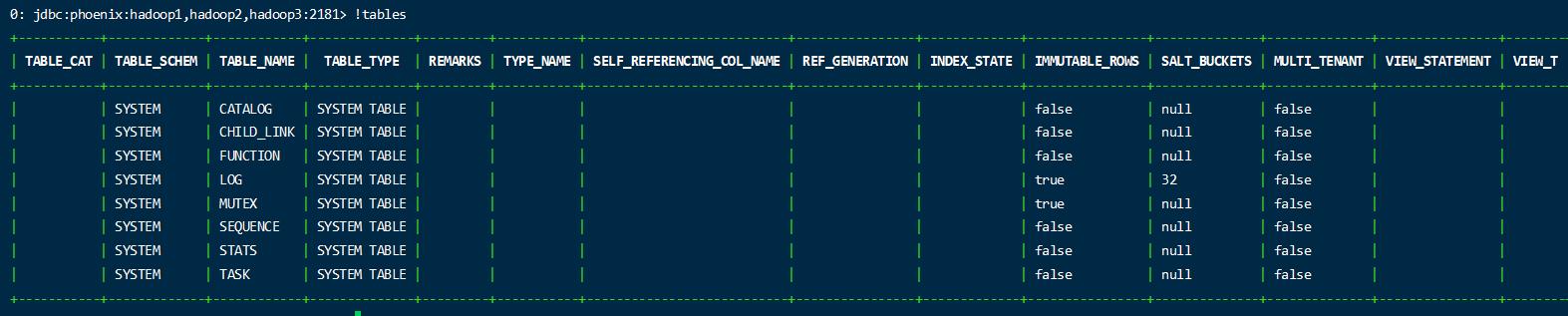
TABLE_NAME 可以表示表的名称
TABLE_TYPE 表示是系统的表还是用户的表
- 创建一个表
创建一个表和基础的sql语法基本相似,主键作为hbase的rowkey
1 | CREATE TABLE IF NOT EXISTS user( |

再查看表可以发现已经有了表的信息了。
同时通过hbase shell 观察下在hbase中创建的数据内容。

可以看到在hbase中创建了一个 USER 表。
- 写入和更新数据
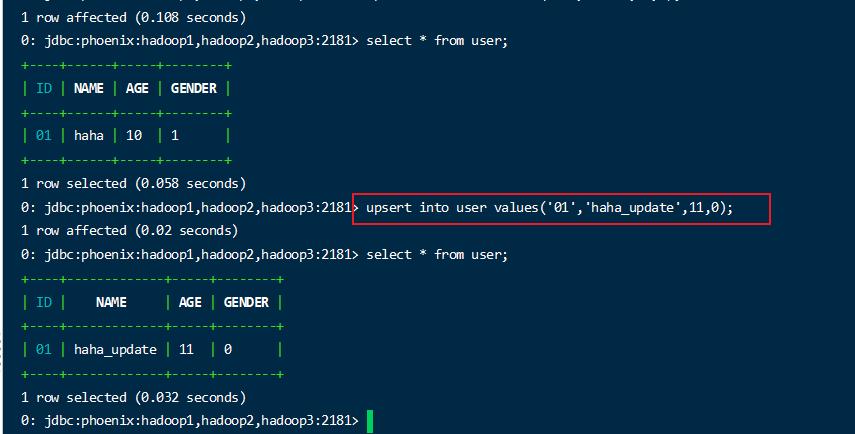
1 | upsert into user values('01','haha',10,1); |
注意:和标准的sql不同的是,插入数据使用的是 upsert,不管是插入和更新都是使用此语句,如果根据主键已经存在那么则会覆盖。
1 | upsert into user values('01','haha_update',11,0); |
已经存在的执行更新
- 删除对应的数据
和基本sql语法一致
1 | delete from user where id = '01' |
- 删除对应的表
1 | drop table user; |
- 从命令行中退出
1 | !quit |
映射表
通过 phoenix 的sql 创建的表,内部已经维护好了映射关系了,但是针对在hbase中已经创建好的数据 是不能直接使用phoenix进行数据操作的,需要先执行数据的映射关系,将表的映射关联起来。
在hbase中创建数据。
1 |
|
通过视图映射
phoenix 视图的方式,视图可用来查询数据但是不能直接操作数据。
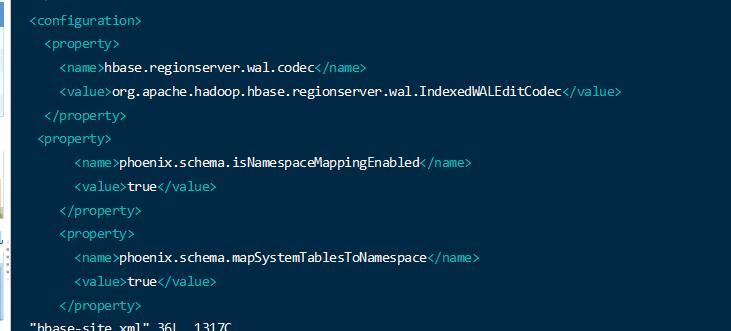
需要注意的是,默认情况下phoenix无法操作非 hbase中 default namesapce 的数据,如果需要将hbase的namespace 的概念和phoenix sechema 对应起来,需要开放一个配置。
在hbase 和 phoenix 的 2个 hbase-site.xml 都需要加上配置
配置文件分别在 hbase_home/conf 和 phoenix_home/bin 目录下
1 |
|
1 | CREATE SCHEMA IF NOT EXISTS data; |

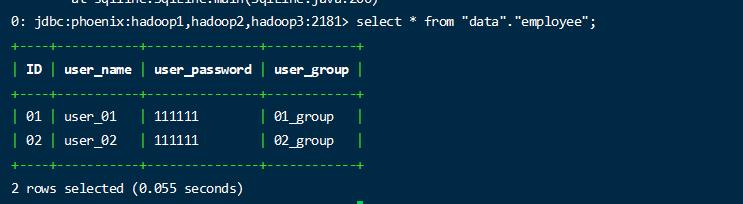
查询数据
1 | select * from "data"."employee"; |
如果这个视图不需要了,可以使用drop 来删除这个视图。
1 |
通过表映射
通过表映射是可以对数据进行修改的。
建立数据
经过测试通过表映射 如果带有SCHAMA ,那么 必须是 大写的,所以hbase的 namespace 也需要是大写的才能对应上。创建视图的时候是可以的,创建表的时候不行,所以 HBASE的namsespace 和
phoenix 的 schema 最好都创建成大写的,避免出现问题。
1 | hbase:062:0> create 'TEST:employee',{NAME => 'info', VERSIONS => 1} |
1 | CREATE SCHEMA IF NOT EXISTS TEST; |
这里有一个很重要的参数 column_encoded_bytes。如果不开启此参数,那么在hbase生成的列将是一个被处理了的比较短的列明,当设置为0 的时候,表示不开启列名的编码,也就能保持两边的列名一致。
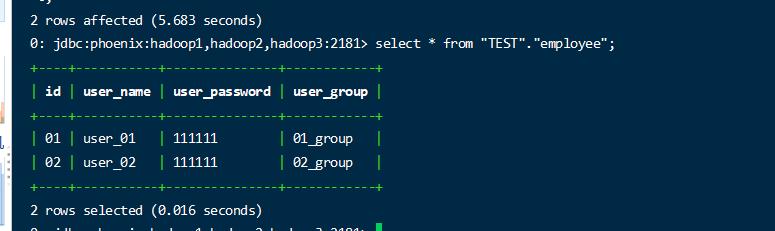
映射成功。
jdbc操作
和普通的jdbc操作基本一致。
- 引入对应的依赖包
1 | <dependency> |
- 编写jdbc基础代码
1 |
|
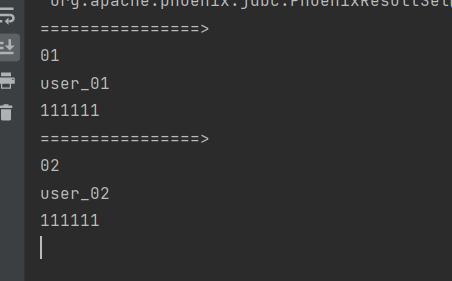
指定的打印结果
Phoenix 二级索引
默认情况下,hbase的数据只能通过 row key 做相关的查询和操作,而如果要能够对其他的字段做高效的查询,需要开启二级索引。
- 修改hbase的配置,为hbase开启二级索引的相关配置。
1 |
|
同步多个节点机器,并重启服务。
全局索引

直接根据一个字段不使用索引查询,显示走全表扫描。
通过 phoenix 创建一个索引。
1 | CREATE INDEX index_1 ON "TEST"."employee" ("info"."user_name"); |

当只查询特定的字段的时候,会有范围扫描。
创建的全局索引会在hbase上创建对应的一个外部索引表。这里创建了一个 TEST:INDEX_1 的表,表的row key 为要创建索引的字段信息。
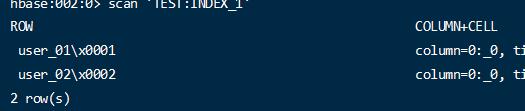
可以看到内部用索引列的信息来创建索引表的rowkey。
索引的删除
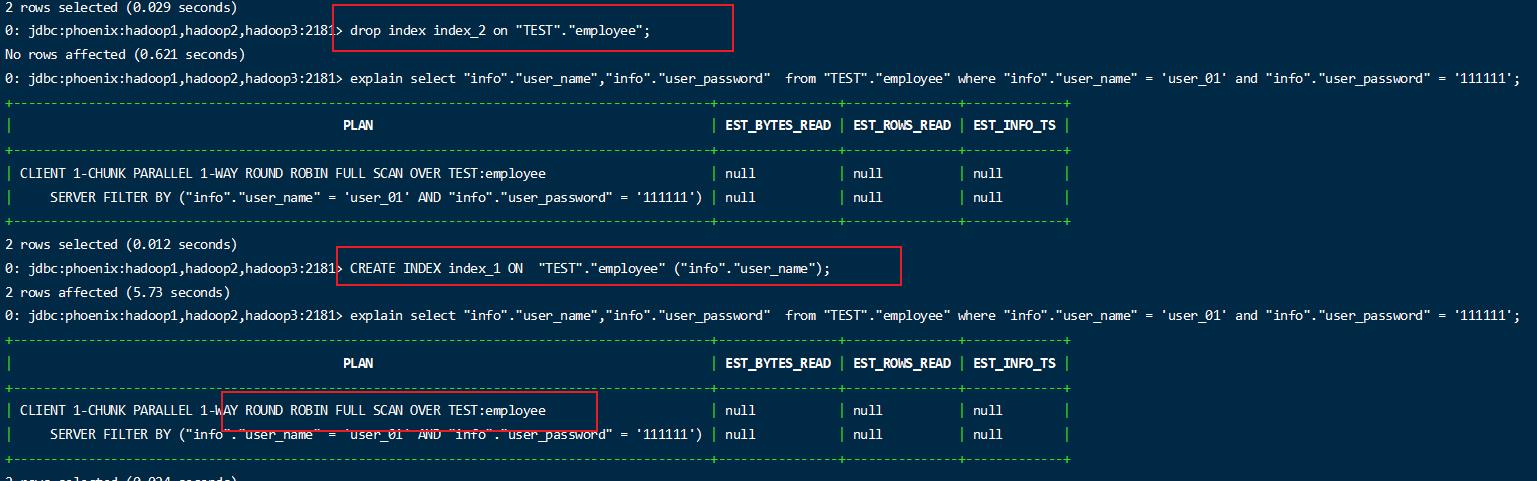
1 | drop index index_1 on "TEST"."employee"; |
全局索引适合读多,写少的场景,因为在操作数据的时候需要同步修改索引数据。
包含索引
包含索引是携带其他字段的索引。全局索引只能有一个字段,包含可以有其他的字段,适合在多条件查询的时候使用。
1 | explain select "info"."user_name","info"."user_password" from "TEST"."employee" where "info"."user_name" = 'user_01' and "info"."user_password" = '111111'; |
创建索引
1 | CREATE INDEX index_2 ON "TEST"."employee" ("info"."user_name") INCLUDE ("info"."user_password"); |
1 | explain select "info"."user_name","info"."user_password" from "TEST"."employee" where "info"."user_name" = 'user_01' and "info"."user_password" = '111111'; |
再次查询

这种有2个字段查询的,如果只用一个字段的全局索引是无法走索引的。
删除此索引,再创建一个单值索引,下图,无法走索引.
本地索引
全局索引的索引表和数据表是分开的,有可能存在不同的region。而本地索引的索引数据是存在于数据表中的一个列上的,所以相对来说是本地的索引。优点是在写操作的时候能够降低写入的开销,不过缺点是没有全局索引的速度快。
创建一个本地索引
1 | CREATE LOCAL INDEX index_3 ON "TEST"."employee"("info"."user_name","info"."user_password"); |
1 | explain select "info"."user_name","info"."user_password" from "TEST"."employee" where "info"."user_name" = 'user_01' and "info"."user_password" = '111111'; |
查看生效

错误: 在创建的时候出现如下错误
org.apache.hadoop.hbase.DoNotRetryIOException: org.apache.hadoop.hbase.DoNotRetryIOException: ERROR 102 (08001): ERROR 102 (08001): Malformed connection url. :hadoop1:2181,hadoop2:2181,hadoop3:2181:2181:/hbase; TEST.INDEX_3
at org.apache.phoenix.util.ServerUtil.createIOException(ServerUtil.java:106)
at org.apache.phoenix.coprocessor.MetaDataEndpointImpl.createTable(MetaDataEndpointImpl.java:2178)
at org.apache.phoenix.coprocessor.generated.MetaDataProtos$MetaDataService.callMethod(MetaDataProtos.java:17317)
at org.apache.hadoop.hbase.regionserver.HRegion.execService(HRegion.java:8773)
需要修改hbase的配置文件,将前面2个的端口号去掉。
修改hbase配置文件 hbase-site.xml
1 | <property> |
修改为
1 | <property> |
hbase服务重启,然后重新连接建立索引即可。

