
hbase(五)hbase分区和优化
分区
hbase直接通过制定规则来决定数据再各个regionServer的分布情况。可以得知数据越是均匀分布,读取性能应该是更好的。
手动分区
通过手动指定分区的规则的形式对数据进行拆分。
- 创建表的时候指定分区规则.
1 | create 'one:sp_1',{NAME => 'info', VERSIONS => 1},SPLITS => ['10','20','30'] |
此规则分成了4个区间,根据对应的row key 分为4个区。
插入数据


可以看到切分了4个分区,并且还有具体的region的分布情况。
- 生成16进制序列预分区.
此种方式只需要指定分区的数量,系统自动根据一定的规则来进行分区。
1 | create 'one:sp_2','info',{NUMREGIONS => 5, SPLITALGO => 'HexStringSplit'} |

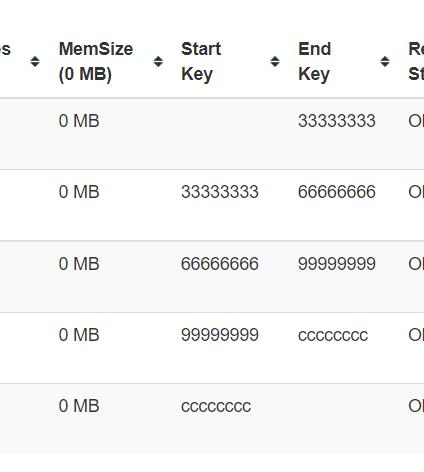
可以看到分区是根据十六进制字符来进行分区的。
- 根据规则文件进行分区。
其实这种分区方式和第一种基本一样,只不过参数变成了一个文件。
编写文件
1 | 10 |
1 | create 'one:sp_3','info',SPLITS_FILE => 'splits.txt |
自动拆分
当前的RegionServer 该表只有一个 Region, 2 * hbase.hregion.memstore.flush.size 分裂,否则按照hbase.hregion.max.filesize 分裂。
优化
rowKey 优化
rowkey的主要作用是防止数据的倾斜,同时能够根据rowkey 高效的查询业务的数据。
所以rowkey 可以使用几种常见的几种方案。
- 随机数,hash值
这种方式能够有效的防止数据倾斜,不过因为key 是没有业务属性的,无法完成一些高效业务查询。
- 时间戳反转
对于一个时间戳的格式是 1661246087615 这种格式,但是这样有个问题,针对一些新的数据会排在后面,
我们在查询的时候希望优先获取较新的数据。
所以通过 99999999999 - 1661246087615 得到一个时间的反转值 作为对应的数据key 可以 优先获取较新的数据。
- 字符串拼接
通过一些字符串拼接来得到一个指定的key,可以将业务数据和随机数据比如日期拼接一个对应的key。
参数优化
- zk 超时时间
zookeeper.session.timeout 超时时间
hbase.client.pause(默认值 100ms) 等待时间
hbase.client.retries.number(默认 15 次) 重试次数
- hbase.regionserver.handler.count rpc 监听数量

