
hbase(四)hbase原理和工作流程
hbase 原理
Hmaster 架构
HMaster是 HBase集群的主节点,负责整个集群的管理工作。
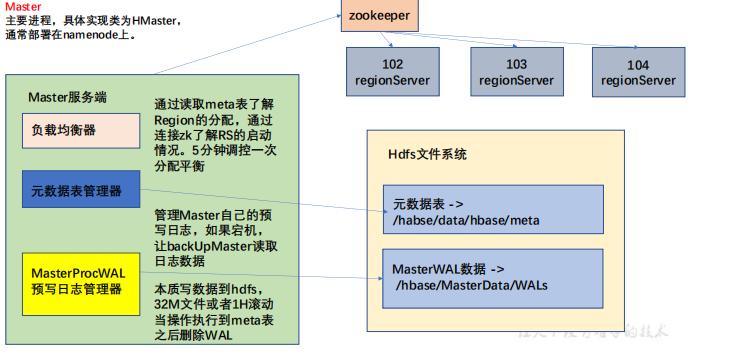
- 分配Region:负责启动的时候分配Region到具体的 RegionServer;
- 负载均衡:一方面负责将用户的数据均衡地分布在各个 Region Server 上,防止Region Server数据倾斜过载。另一方面负责将用户的请求均衡地分布在各个 Region Server 上,防止Region Server 请求过热;
- 维护数据:发现失效的 Region,并将失效的 Region 分配到正常的 RegionServer 上,并且在Region Sever 失效的时候,协调对应的HLog进行任务的拆分。
- 预写日志管理,master 会将master的相关操作写入 maste的WAL 日志中。当master 挂了后,由backUp Master根据日志内容继续操作。
hdfs 中的 /hbase/MasterData 目录下存放的是 master 相关的数据。
hbase:meta 这个表中记录了元数据信息,这个表的数据由master来进行写入,meta中记录了各个表的元数据信息,是由master来对meta数据进行管理。
同时这些meta信息会在zk中的一个节点上存储一份,当数据读写操作需要获取mata信息的时候是通过zk中的数据来获取元数据信息的。
RegionServer架构
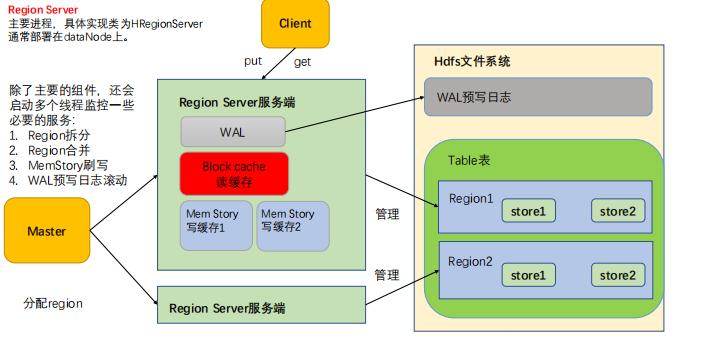
regionServer 是用来执行工作的服务,是直接跟hdfs交互处理和写入数据的。
在regionServer中有几个相关的组件。
- WAL 预写日志
WAL预写日志的主要作用是防止数据丢失,在写数据的时候首先向WAL中写入成功后,再执行写入,在写入过程中出现宕机也可以由其他接管的regionServer继续完成写入操作。
同时WAL可以保证写入的顺序问题。
- BlockCache读缓存
查询的数据在RegionServer中有一个缓存,在缓存有效期内再次请求这个数据,会直接从RegionServer的缓存中获取。
- StoreFile 存储文件
StoreFile 底层实现是HFile,是数据的物理存储单位。
- MemStore 内存存储,写缓存
写到StoreFile 的数据必须是有顺序的,所以数据并不直接写到StoreFile,而是先写到MemStore,在MemStore完成排序的处理,当MemStore的文件达到一定的条件后,溢写到对应的StoreFile 上。
StoreFile 和 MemStore 的关系是一对一的关系,一个MemStore溢写成一个StoreFile。
同时RegionServer还有 Region拆分,Region合并,MemStore刷新,WAl预写日志刷新的相关功能。
客户端初始化流程
客户端的Connection 对象是一个比较重量级的客户端,在创建的时候涉及到一系列和服务端的数据交互。
调用 org.apache.hadoop.hbase.client.ConnectionFactory.createConnection(config) 完成一个初始化连接对象。
客户端向zk 发送请求创建连接。
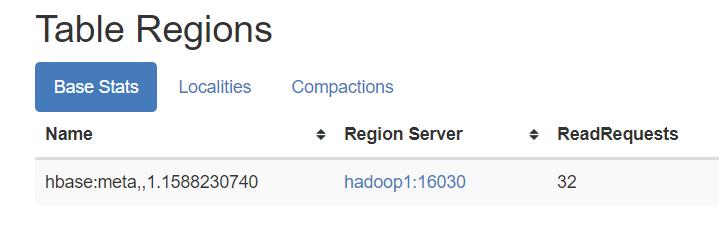
读取zk中的信息的meta 表是由哪个RegionServer存储的
将读取的meta表缓存在客户端的MataCache 中。

从上图可以看出zk中保存的meta表的信息存在region1中。
写流程
- 客户端初始化后,从meta 表获取当前要写入的表对应的region被哪个regionServer管理,连接对应的region,开始写入数据。
- 服务端数据顺序写入到 WAL ,此处写入直接落盘,并有专门的线程控制wal的日志的滚动。
- 根据写入的Rowkey 和 columnfamily 查看具体写入到哪个MemStory,并且在MemStore中排序
- 写入完成后服务端向客户端响应ack
- MemStore 达到刷新的条件后将数据刷新到对应的store中。
MemStore 刷新条件
刷新与MemStore文件大小的关系
大小开始刷:memstore 大小 > hbase.hregion.memstore.flush.size(128M) 开始刷写
大小阻止写:memstore 大小 > hbase.hregion.memstore.flush.size * hbase.hregion.memstore.block.multiplier(默认4) = 512M 开始阻止向Memstore中写数据刷新与java_heap_size 内存的关系
内存开始刷: java_heapsize * hbase.regionserver.global.memstore.size(默认值 0.4) 开始刷
内存阻止写: java_heapsize * hbase.regionserver.global.memstore.size(默认值 0.95)阻止写时间足够长触发刷写
hbase.regionserver.optionalcacheflushinterval(默认1 小时) 长时间不刷写的最大时间,超过此时间开始刷写
存储文件结构
Hdfs中实际存储的文件信息包括
- 数据本身 key value
- 元数据信息
- 文件信息
- 数据索引
- 元数据索引
- 固定长度的尾部信息
通过hbase 自带命令工具可以解析存储文件。
1 | ./hbase hfile -m -f /hbase/data/one/user/cba9993e8c776c0629ca420687dc205a/info/8b4a70ebfe2a4dd7b819d790d0d10955 |
1 | Block index size as per heapsize: 320 |
数据的键值对信息是按照块大小(64k)保存在文件中的。
数据的索引是按照数据的块来创建的。
读流程
- 数据通过连接获取Table 对象。
- 从Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
- 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到Block Cache。
- 将合并后的最终结果返回给客户端。
内部读取优化
合并读取优化
- hfile 带有索引文件,读取rowKey 比较的快。
- block cache 会缓存之前的内容和元数据信息。
- 使用布隆过滤器能够过滤当前hfile不存在需要读取的rowkey,从而避免读文件。
Storefile 合并
Storefile 会定期执行合并。
分为 是 Minor Compaction (小合并) 和 Major Compaction 大合并。
小合并是将一个小文件和附近的小文件合并为相对大的文件,而大合并是将一个store下的所有hfile 合并为一个大Hfile,并清理掉过期和删除的数据。

