
jvm知识点总结
jvm知识点总结
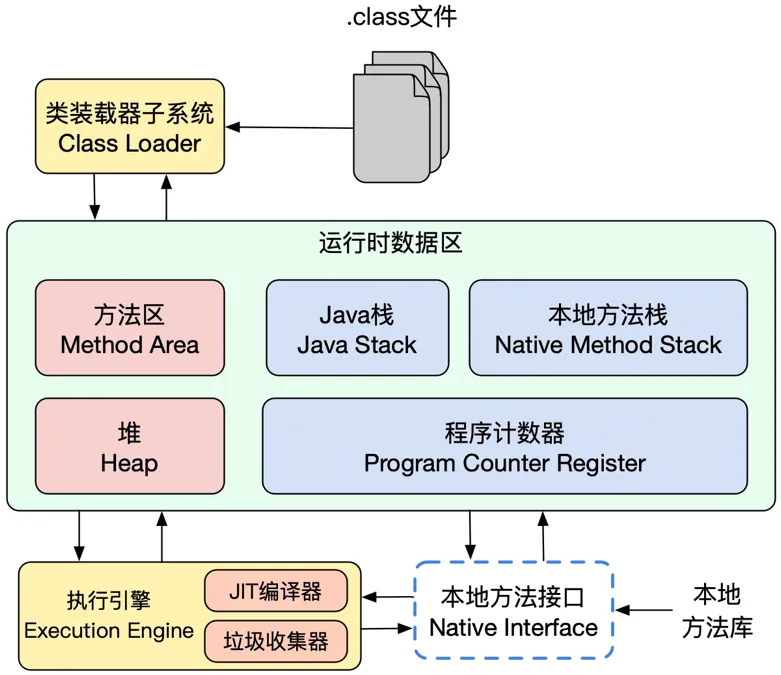
jvm组成
- 类加载器 负载从磁盘上加载类
- 运行时数据区 存放运行时的数据
- 本地方法接口 调用本地的接口
- 执行引擎 即时编译器 和GC
类加载的过程
- 加载 类加载器classload从磁盘上将字节码文件加载到内存放入
- 验证 校验字节码的格式的正确性
- 准备 给类的静态变量分配内存和默认值,基本类型的默认值,引用类型赋值为null
- 解析 将符号引用替换为直接引用,该阶段会把一些静态方法(符号引用,比如main方法)替换成指向数据所占内存的指针或句柄等(直接引用),这是所谓的静态链接过程(类加载期间完成),动态链接是在运行的期间将符号引用替换成直接引用。
- 初始化 对类的静态变量初始化为指定的值,并执行静态代码块
- 使用 正常执行代码逻辑
- 卸载 引用不存在,gc销毁
jvm中的类加载器
- BootstrapClassLoader 加载jre lib目录下的class
- ExtClassLoad 加载jre lib 下的ext目录下 parent = BootstrapClassLoader
- AppClassLoad 加载classpath目录下的class parent = ExtClassLoad
- Custom ClassLoad 加载自定义的目录下的class
每个classload 都有一个parent属性
内置classload 源码地址
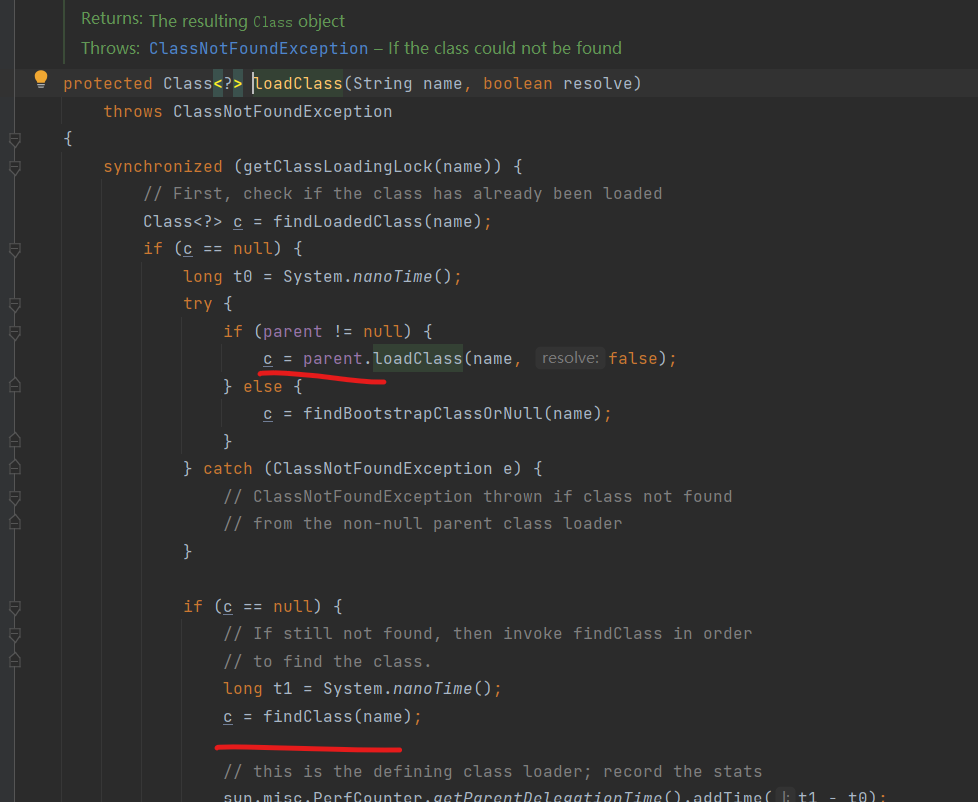
双亲委派机制
简单的说就是加载类的时候先用自身的父类加载器去加载,父加载器加载不到的时候再由自身去加载。
这么做的好处:
- 沙箱安全机制,自己写的和jdk类型同名的类不会被加载,防止核心类库被篡改
- 避免重复加载,类由父加载器,加载过了,就不再由子加载器重复加载了,确保被加载类的唯一性
打破双亲委派机制
有时候是需要去打破此机制的。
比如tomcat为了实现隔离性和热替换,没有使用默认的类加载器,而是自己实现了类加载器。
针对不同的项目使用不同的类加载器
如何自定义类加载器
- 继承classLoad类
- 重写findClass方法
- 自定义的classload的parent 是appclassload
jvm 内存模型
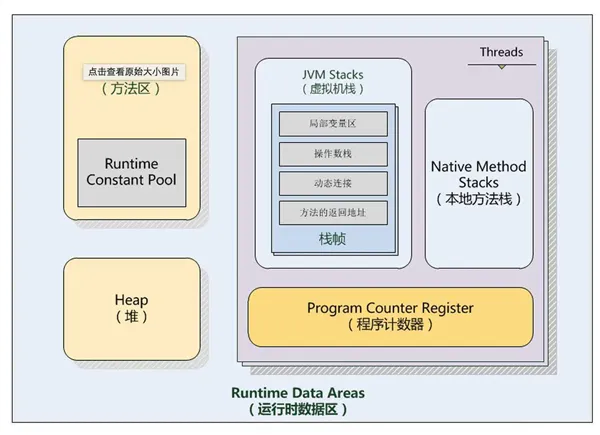
堆
创建的new 出的对象都存在堆中,所有的线程共享空间
栈(线程栈)
每一个线程创建的时候,就在栈开启一个线程的栈空间;
栈空间由一个一个的栈帧组成。每个栈帧 包含了 局部变量表, 操作数栈, 动态链接, 方法出口。
局部变量表: 类似于数组的一种数据结构,存储了局部变量的值;用来存放方法参数和方法内定义的局部变量.
操作数栈:操作数栈是一个用于计算的临时存储区域;在方法开始执行后,从局部变量表中或对象的实例对象中复制常量或变量到操作数栈,再随着计算将栈中元素出栈到局部变量表或返回给方法调用者
动态链接: 就是将方法的符号,执行方法的内存地址;一个方法要调用另一个方法,需要将这些方法的符合转化成其在内存地址中的直接引用,符号的引用存在方法区的运行时常量池。
方法出口 方法执行完毕,从栈帧中弹出
元空间
存放对象的class 和结构等信息,jdk1.8之前有个词叫做永久代;1.8之后改名为元空间,用的是直接的内存,即物理内存
存放的信息由
- 加载的类文件
- 常量
- 静态变量 静态变量的引用还是指向堆空间
本地方法栈
调用本地方法的栈
程序计数器
在每个栈中都分配一块程序计数器的空间,用来指示代码执行的位置和行号等信息。
对象的创建过程
类加载检查 首先检查类是否被创建过或加载过,如果没有就让类加载器加载此类
分配内存 在堆中分配一块内存空间。分配的方式根据内存规整分为2种方式,如果内存规整就使用 指针碰撞的方式,如果内存不规整就使用空闲列表的方式。其中可能出现并发失败的问题,
如果出现失败的情况下, 通过 1 cas 重试 2. tlab 本地线程分配缓冲的方式初始化 内存分配完成后,虚拟机将分配到的内存空间都初始化为零值
设置对象头 设置对象头的信息,比如是哪个类的实例,如果找到类的元数据信息,对象的hash吗,对象的gc分代年龄等
执行init方法 为成员变量赋值,执行静态代码块,执行构造器
对象头的结构
Mark Word Mark Word记录了对象和锁有关的信息。
指向类的指针
数组长度(只有数组对象才有)
对象的分配
栈上分配
对象一般都是在堆上分配空间的,对象的回收依赖gc的回收机制,如果对象比较多的时候会对gc带来压力,为了减少临时对象在堆上分配的数量,通过逃逸分析,判断一个对象是否会外部使用,如果不会被外部使用,就将对象分配到栈上,当方法结束的时候,对象也就被销毁了,不需要gc回收;
什么时候会栈上分配
jvm 会通过逃逸分析要确定是否要栈上分配,分析方法内对象的作用域,确定对象是否只在方法内被使用,是否没有被外部的对象使用。通过参数配置(默认开启) 开启逃逸分析参数(-XX:+DoEscapeAnalysis)
标量替换(优化)
一个对象通过逃逸分析确定是否要分配到栈帧上,但是栈帧空间是比较小的,并且栈帧的空闲空间可能是碎片的,标量替换是向栈帧中放数据的时候不放置整个对象,而是将成员变量放置到栈帧中.(把对象拆开成成员属性,就能放下了)
标量与聚合量: 标量指的是java中不能被分解的量,比如基本数据类型 int long 等,而聚合量指的是可以被分解的对象
对象eden区分配
新创建的对象默认在eden区分配,eden区满了触发一次minor gc,eden区的幸存对象放到survivor 区,当对象在survivor 每次都会年龄+1,大于15岁时,放入老年代,老年代满了触发fullGc
对象的Gc 分为年轻代的 minor gc 也叫YoungGc。 新生代的gc,回收速度比较快。 老年代的 叫做 major/fullGc 特点是 回收慢,耗时长,触发stw。
大对象直接进入老年代
对于一些比较大的对象(需要大的连续的空间操作的对象),超过设置的参数的时候,会直接进入到老年代;主要为了降低大对象的频繁复制降低效率。
(设置大对象的定义值: -XX:PretenureSizeThreshold)
长期存活的对象直接进入老年代
分代年龄达到设置的值(默认15),进入老年代
(-XX:MaxTenuringThreshold=15)
对象动态年龄判断
一批对象的放到survivor 区,当对象的总大小大于总空间的50%;会将一部分对象直接放到老年代,一般在minorGc 后触发。
(-XX:TargetSurvivorRatio)
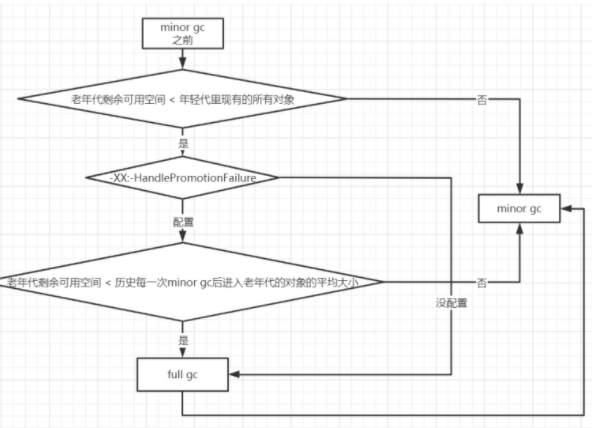
老年代空间分配担保机制
年轻代minorgc 前会计算下老年代的剩余空间,如果发现老年代剩余空间小于年轻代中的对象的空间和;有没有配置这个担保参数,是否小于之前的平均对象,如果大于的时候就直接fulGc了,最后总是要执行minorGc的;(以之前的多次的平均值来计算个是否会发生fullGc的概率)
对象的内存回收
内存回收的方式
引用计数法: 通过在对象上添加一个引用计数器,有引用的时候就+1,无引用了就-1
可达性分析算法: 通过GCRoot 为起点,从节点向下搜索对象,找到的对象是非垃圾对象,未找到的就是垃圾对象
java 中的引用类型
强引用 普通的引用就是强引用
软引用 SoftReference,当gc的时候,空间不够的时候会回收
弱引用 WeakReference,只要gc就回收
虚引用 只要gc就回收, 和引用队列一起使用监控对象的垃圾回收。
判断一个类是无用的类
- 该类的所有实例都被回收,内存中不存在此类的实例
- 加载该类的classLoader被回收(只有自定义的会被回收)
- 该类的java.lang.Class 没有被引用,其他的地方无法通过反射访问该类的方法
垃圾收集算法
分代收集理论
根据对象存活的周期的不同将内存分为几块,一般将java堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。一般新生代使用复制算法,老年代使用标记整理算法。
标记复制算法
将内存空间分为2份,一块使用的,一块空闲的,每次收集将使用的未回收的复制到另一半空闲的。
缺点:浪费空间。
标记清除算法
算法分为标记和清除阶段,先标记不回收的对象,然后回收的时候将未被标记的对象回收
缺点:可能会造成内存碎片,导致大的对象找不到合适的位置。
标记整理算法
分为2个阶段,先标记对象,然后再整理,将不需要回收的对象移动到要回收的对象的位置;
三色标记法
在并发标记过程中,用户线程还在执行,被标记过的对象的指针可能还发生变化,可能发生多标和漏标,为了解决这个问题,使用三色标记法
在gcroots 可到达分析过程遇到的对象,根据是否访问过,分为黑色,灰色,白色的对象;
黑色:被访问,并且所有关联的对象也被访问;
灰色:被访问过,连接的对象还有没被访问过的;
白色:还未被访问过
多标-浮动垃圾
在并发标记的过程中,已经被标记成黑色的对象由于方法执行完毕,gcroot销毁,就成了浮动垃圾;浮动垃圾对系统没有影响,下次清理。
针对并发标记(还有并发清理)开始后产生的新对象,通常的做法是直接全部当成黑色,
漏标-读写屏障
漏标会导致有引用的对象被误删除,可能在标记过程中黑色和白色的连接加上
针对漏标的解决方案
增量更新(increment update)
在并发标记过程中产生的指向白色对象的黑色对象,记录下来,从这些黑色对象为出发点,再扫描一次;(黑色对象连接的白色对象就一定至少变为灰色了);
比如cms 的再次标记
原始快照(snapshot At The beggining)
原始快照关注的被删除的引用,在引用被删除之前将之前的快照的引用保存起来,再重新标记的时候会被标记为黑色(可能成为浮动垃圾)
垃圾收集器
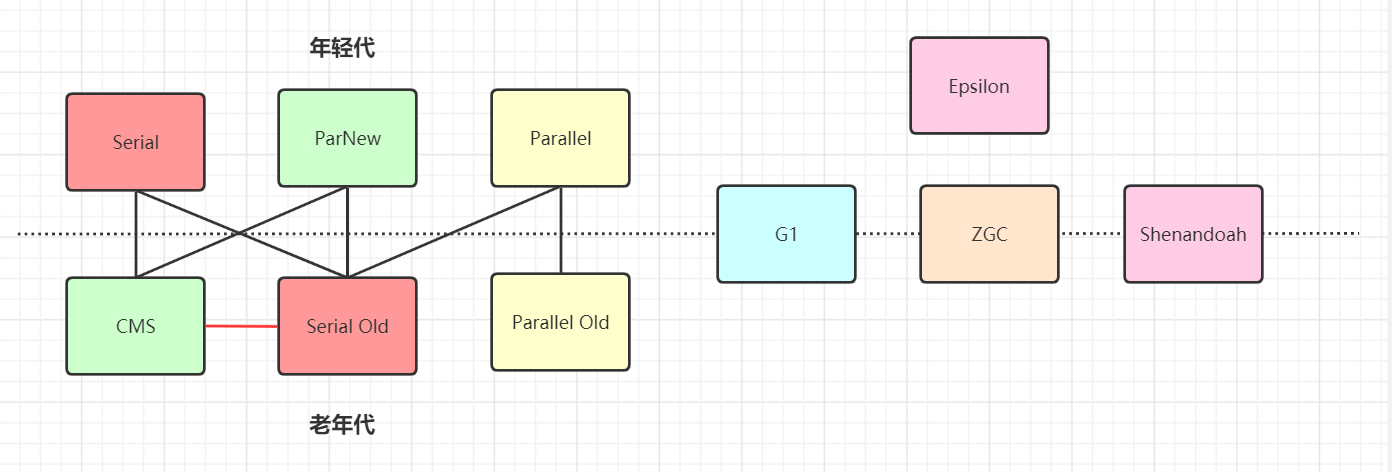
常用垃圾收集器图示
Serial(串行的)[年轻代]
serial 是基本的,历史悠久的垃圾收集器,是一个单线程的垃圾收集器,在收集的时候时候单线程。
算法:年轻代 - 复制算法
优点:简单,高效
缺点: 会发生stw
Serial Old(串行的)[老年代]
serial 收集器的老年代版本,单线程执行。
算法:老点代 - 标记整理算法
优点:简单,高效
缺点: 会发生stw,效率慢
parallel scavenge(平行的收集器)[年轻代]
parallel 是 serial收集器的多线程版本,默认收集线程和cpu核数相同。
算法:年轻代 - 复制算法
优点: 并行执行,吞吐量比较高。
缺点: 回收过程发生stw
parallel scavenge Old(平行的收集器)[老年代]
parallel scavenge 老年代版本。
算法: 老年代 - 标记整理
优点: 并行执行,吞吐量比较高。
缺点: 回收过程发生stw
ParNew [年轻代]
和 parallel收集器类似,多线程并行执行。
算法: 年轻代 - 复制算法
优点: 充分利用多核cpu资源,可以和cms配合使用
缺点: 回收过程发生stw
CMS (Courrent Mark SWeep)[老年代]
cms是一种以获取最短回收停顿时间为目标的收集器,非常符合注重用户体验的应用上使用,hotspot第一款真正意义的并发收集器,实现了让垃圾收集与用户线程(基本上)同时工作;
算法: 老年代 - 标记清除
优点: 并发收集,低停顿
缺点:
- 对cpu资源敏感(和用户服务抢资源)
- 无法处理浮动垃圾 (并发清理中可能产生浮动垃圾)
- 标记清除算法会有空间碎片产生
- 回收过程的不确定性,会存在一次垃圾收集还未完成,然后垃圾回收又被触发的情况
cms 的内存碎片问题,可以配置FullGC之后做压缩整理参数,执行压缩。
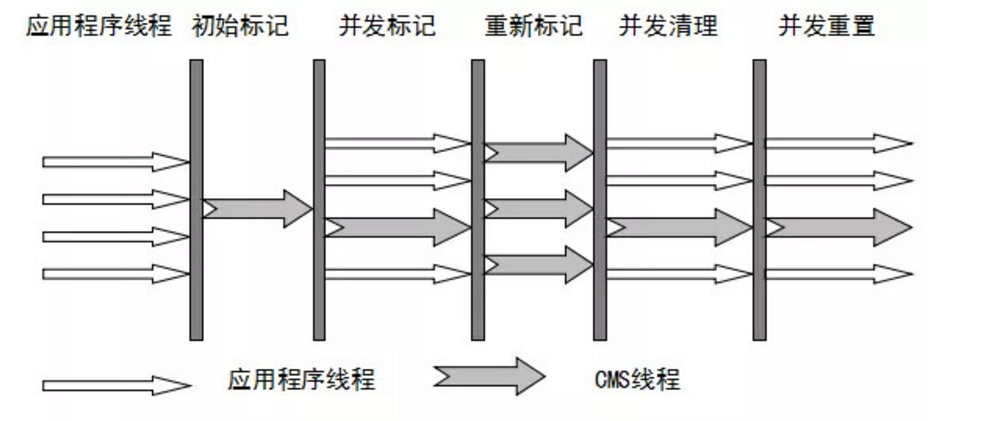
回收过程
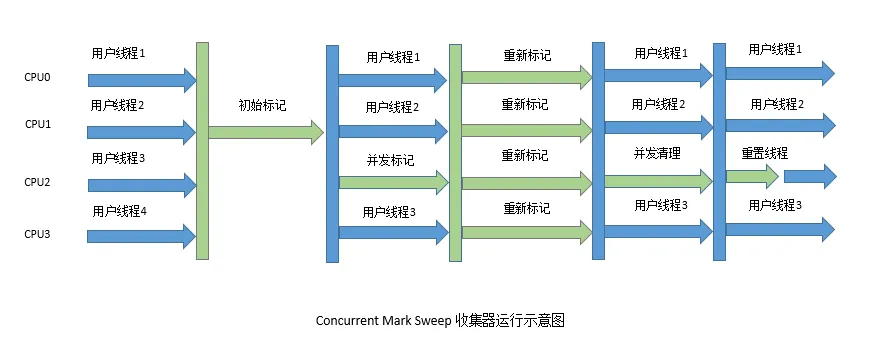
- 初始标记
会stw,从gcroot出发找到能直接达到对象 - 并发标记
从初始标记找到的对象沿着对象图依次找能够到达的对象,多线程并发执行,期间不需要stw,可以跟用户线程同时执行;在标记过程中对象的状态可能发生改变 - 重新标记
因为在并发标记的过程中一些对象的状态可能发生了改变,可能又产生了一些垃圾,重新标记用来标记并发标记过程后的残留的对象.重新标记的时候会stw,时间比初始标记时间长,比并发标记时间短. - 并发清理
对未标记的垃圾进行并行清理; - 标记重置
重置本次gc过程中的标记数据;
CMS concurrent mode failure 问题
可能触发 concurrent mode failure ,由serial old 垃圾来回收。
一旦触发此机制,会由性能比较差的serial old 来回收垃圾。
在执行并发标记或并发清理等过程中,可能有新的大对象被放到老年代,或已经达到最大分代年龄的对象到老年代,但是老年代已经没空间了,就会触发fullGc;在stw状态下由serial old 执行回收;
G1(garbage-first)[年轻代 + 老年代]
g1 是面向服务器的垃圾收集器,主要特点是满足gc低停顿的同时满足高吞吐量,可以通过设置期望的最小停顿时间。
算法: 标记整理算法
结构
g1将内存分成多个region,一般是2048个,或手动调节(-XX:G1HeapRegionSize),新生代,老年代分布在不同的region,不再是连续的内存空间了.
物理区分 转向 逻辑区分。 年轻代占据5%,系统运行中年轻代的空间会自动调节,但是不会超过最大设定值; eden和survivor 的比例仍然是8:1:1
humongus:g1专门用来存放大对象的区域;如果一个对象超过一个region的50%,就认为是大对象,被放到这个区域,而不是进入老年代,在gc回收的时候,这个区域也会被回收。
回收过程
gc 过程和cms类似,分为初始标记–》 并发标记 –》 最终标记 –》 筛选回收
筛选回收会根据region回收价值和成本排序,同时根据用户指定的停顿时间,制定回收计划为了最小的时间,回收更多的region区域.
特点
- 并行与并发 充分利用多核cpu资源,允许并发执行,尽量减少stw时间
- 分代收集 保留分代收集概念
- 空间整合 与cms的标记清理算法不同,g1从整体上看是基于标记整理算法实现的收集器,从局部上看是基于复制算法实现的
- 可预测的停顿 G1追求低停顿,同时建立可预测的停顿时间模型,能让使用者明确指定在一个时间段内完成收集
多种GC
- youngGc 计算eden区的垃圾回收需要的时候,如果还没达到允许的停顿时间,就不回收,等垃圾回收需要的时候达到了停顿的时间的时候,才回收.
- MixedGC 当老年代的空间达到某个阈值的时候触发,回收年轻代和部门老年代,主要通过复制的方式将一个region复制到另一个region,如果没有空间就触发fullGc
- FullGC fullGc 的时候会使用serial单线程执行,非常的慢;
zgc
zgc是jdk11中加入的具有实验性质的低延迟垃圾收集器;
ZGC收集器是一款基于Region内存布局的, 暂时不设分代的, 使用了读屏障、 颜色指针等技术来实现可并发的标记-整理算法的, 以低延迟为首要目标的一款垃圾收集器
特点:
- 支持TB量级的堆
- 最大GC停顿时间不超过10mm
- 最大GC停顿时间不超过10mm
- 最糟糕的情况下吞吐量会降低15%
缺点: 在jdk11 还不推荐使用,目前也还不支持分代。
zgc结构
和g1 一样,内存结构基于region。
根据region的大小不同,又分为了
大型region
容量不固定,可以动态变化,但必须为2M 的整数倍,放置4M以上的大对象;中region
固定为32M的空间,存放大于256k小于4M的对象
小region
固定为2M,存在小于256K的对象
垃圾收集官方文档
jvm 常用参数
jvm参数分为3类
- 标注指令 - 开头,所有HotSpot 都支持,可以使用java -help打印出来
- 非标准指令 -X 开头, 跟特定的HotSpot版本对应,可以使用java -X 打印出来
- 不确定参数 ,变化非常大,JDK1.8下有几个常用的不稳定指令
java -XX:+PrintCommandLineFlags : 查看当前命令的不稳定参数
java -XX:+PrintFlagsInitial: 查看不稳定参数的默认值
java -XX:+PrintFlagsFinal 查看不稳定参数的最终生效的值
常用的jvm参数
1 | -Xms2g 最小堆 |
优化参数:
-server
服务端模式
-XX:-OmitStackTraceInFastThrow 快速异常详细打印 ,配置内存溢出导出和heap地址
-XX:+HeapDumpOnOutOfMemoryError 有异常就输出
-XX:HeapDumpPath=%LOG_PATH%\crm_heapdump.hprof
-XX:-UseLargePages 使用大内存分页
使用gc
cms
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC 用cms搭配parnew
-XX:+UseCMSCompactAtFullCollection:FullGC之后做压缩整理(减少碎片)
使用cms的参数示例
1 | -server -Xms2g -Xmx2g -Xmn1g -Xss1024k -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m -XX:-OmitStackTraceInFastThrow -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=%LOG_PATH%\jvm_heapdump.hprof -XX:-UseLargePages -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:+UseParNewGC -XX:SurvivorRatio=6 |

