
网络基础(四)网络层
网络层
网络层要解决的问题是数据在计算机之间的通信。
网络层传输的单位是IP数据包(packet)。
以太网帧的数据部分很多时候是由网络层传递的网络层的数据包。而网络层的数据包也有对应的头部和数据部分,数据部分是由传输层传递的。
网络层的数据可能不能由网络层传递的,比如IMCP协议 ,ARP协议,直接在网络层工作的。
网络层的结构
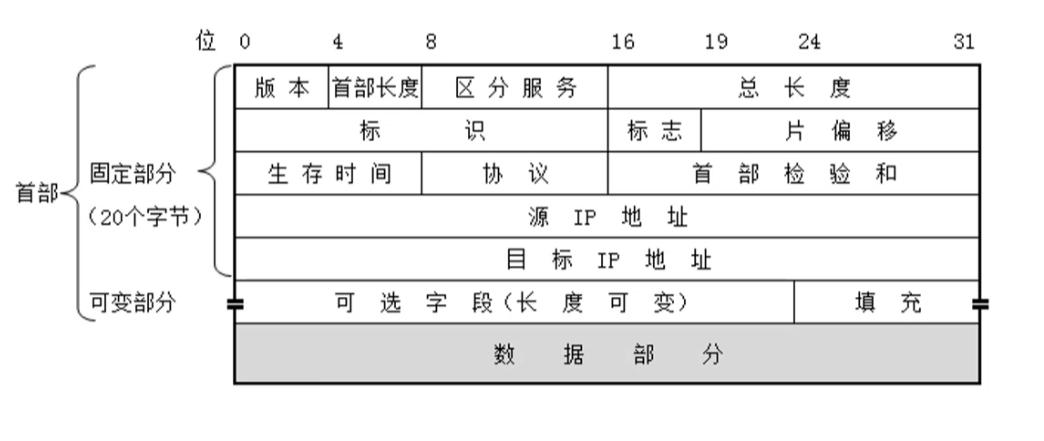
IP数据包的结构图
- IP数据包 由 头部 和 数据部分两部分组成。
- 因为以太网的首部 后是数据部分,所以以太网首部紧跟着就是网络层的首部。
版本 (4)
版本记录了传输的是ipv4 还是ipv6 。如果是ipv4 值就是0b0100 ipv6就是0b0110
首部长度(4)
版本加首部 占用
指的是当前的首部部分的长度是多少。(注意这个首部长度因为存储空间有限存储的是 实时大小 / 4 的值) 值在20 到60之间。
区分服务(8)
区分服务是可以在这个位置添加一个服务标识,在路由器设置特定网络标识的数据包优先通过。设置数据包的优先级。
总长度(16)
指的是 数据包首部 + 数据部分的总长度之和,最大的值是65535.
标识(16)
当数据包分片的时候,同一个包的分片数据包的此id是一样的。
标志(3)
此标志主要用在数据分片的地方。
共有3位的数据
第一位数据保留,暂时无用。
第二位如果是1 标识不允许分片,0 代表允许分片。(默认允许分片,也可以手动设置不允许分片)
第三位 如果是1 表示不是数据包分片的最后一个数据包,如果是0 表示已经是最后一个数据包了。
片偏移(13)
片偏移主要用来记录当前的分片数据包在整个数据包的偏移字节数。
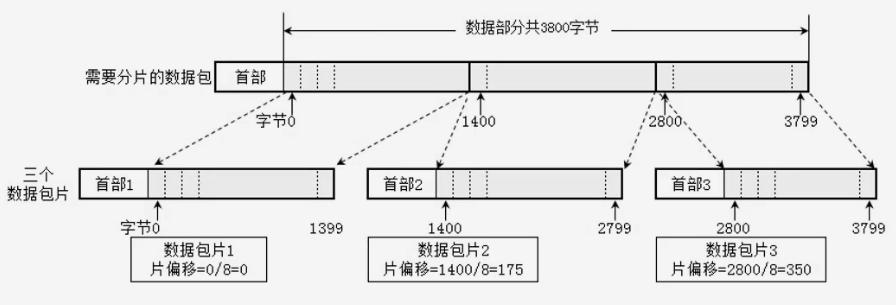
当数据包被切分成多个数据包(fragment)后,在每个片数据包的头部记录自身数据包在原始数据包中的偏移值。
注意在存储的时候是用真实偏移 / 8 存储的,计算的时候需要乘以8
生存时间(8)
TTL (Time To Time)
在执行ping 命令的时候会发现有这么个值。
此值的含义是 有一个在发送命令之前给定一个初始值,每次经过一个路由器转发,TTL的值减去1,当TTL为0 的时候,返回超时错误。
TTL 的初始值跟操作系统有关

TTL 可以防止在路由器配置错误的时候的死循环。能够停止死循环传输。
协议(8)
表明了封装的数据适用了什么协议

协议和值的对应关系
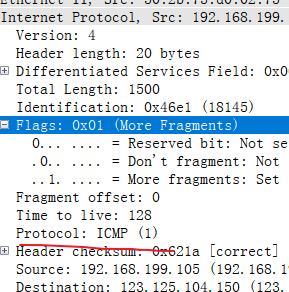
通过抓包ping 的请求可以看到
首部校验和(15)
将首部的数据计算出来的一个值。校验数据的正确与否。
源IP地址(4)
发送方ip地址
目标IP地址(4)
发送目标的ip地址
数据分片传输
因为网络层整个数据包是作为数据链路层的 帧的数据部分,而数据链路层的帧的数据部分长度限制是1500字节,所以需要这里的总长度过大,超过了1500个字节,会将数据包拆成多个分包传输。
分成多个片的传输每个片都有自己的网络层首部。
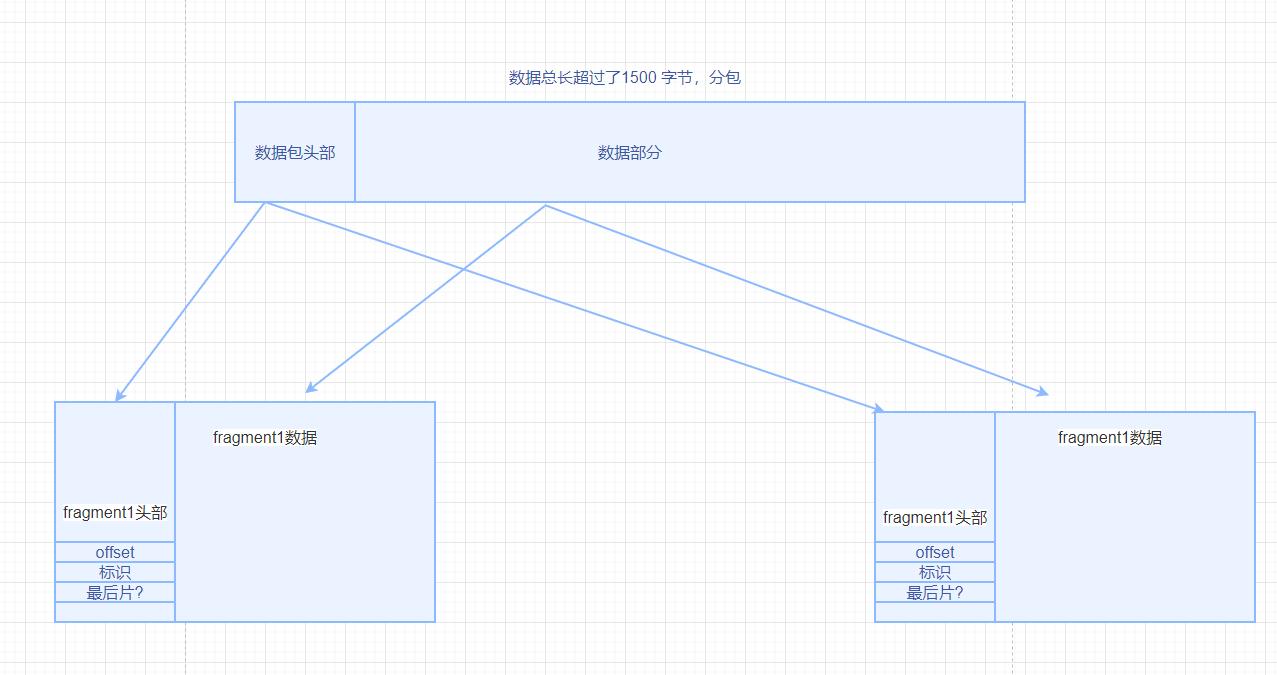
- 解析每个分片包的时候,通过标识确定那些段一个数据包
- 通过offset 片偏移,确定数据的顺序
- 通过是否最后一个片,确定数据包的结束标识
IPV6
IPV6(Internet Protocol version 6):网络协议第六版。
ipv4 的长度是32位的,而ipv6为了解决ip地址不足的问题,设计成了128位的。
ipv6格式
ipv6地址为 128bit,每16bit一组,共8组。每组以4位16进制方式表示。
例如 : 2001:0db8:86a3:08d3:1319:8a2e:0370:7344
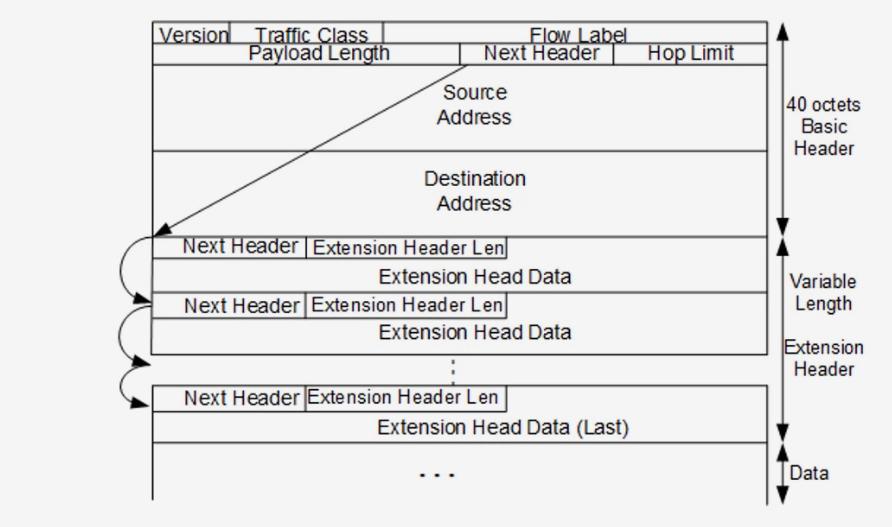
首部格式对比

从上图可以看出,ipv4的头部信息很多都做了删除,ipv6仅仅是多了一个Flow Label,其他的头部字段很多和ipv4 的作用相同。
ipv6的首部比ipv4更加的精简,性能也提高了需要。
version 版本号 (4bit),表示ipv4 还是ipv6
Traffic Class 交通类别(8bit),指示数据包的类别和优先级,可以帮助路由器根据数据包的优先级处理流量。假如发生拥堵,那么低优先级的数据包将被丢弃。
payload length 有效负载长度(16bit), 包括拓展头部,上层(传输层) 数据的长度。
payload length + 固定头部 = 整个数据包的大小
Hop Limit 跳数限制(8bit),和ipv4中的ttl相同。
Source Address(128bit),源ip地址
Destination Address (128bit),目标ip地址
Flow Label 流标签(20bit),用来指定数据包属于那个特定的序列(流),用数据包的源地址,目标地址,流标签来识别一个流。
Next Header 下一个头部(8bit),指示拓展头部的类型,上层数据包的协议类型。(TCP,UDP,ICMPv6 )
规定了一些数据的类型。
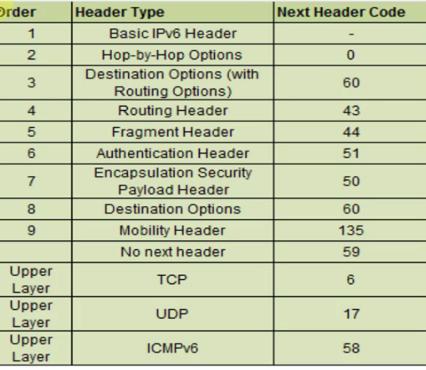
假设整个数据包是有拓展头部的。
第一个NextHeader 的类型是 43 ,那么就知道 头部紧接着的拓展头部的类型是什么,并且占用多大的字节。
而没有拓展头部内部都有一个Next Header
找到第一个拓展头部的时候,通过这个拓展头部的Next Header 去获取下一个拓展头部的类型,如果有就接着解析,如果类型是 TCP ,UDP ,ICMPv6 ,那么就说明接下来的数据已经不是拓展头部了,是上层的数据,属于当前层的数据部分。
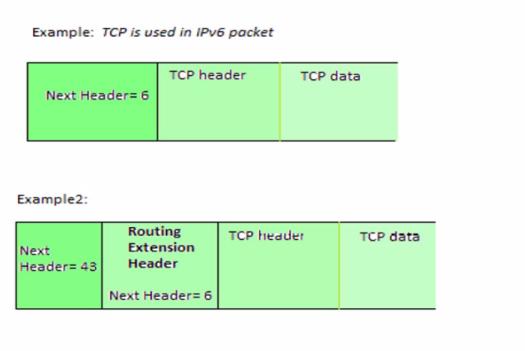
example1 是没有拓展头部,example2 是有一个拓展头部,接着就是tcp数据部分。具体的nextHeader 的值的类型可对照上面的表查看。
ipv6的优点
更大的地址空间
更高效的路由
IPv6聚集减少了路由表条数,分层使路由更加高效。在IPv6网络中,数据包分片是由源节点而不是中间路由器来处理,提升了IPv6转发效率。
更高效的数据包处理
ipv6不包含ip级别的校验和,不用再每个路由节点计算校验和。
测试
查看数据包分片
1 | ping sina.com.cn |

查看到响应IP,通过wireshark 抓取此ip的网络包
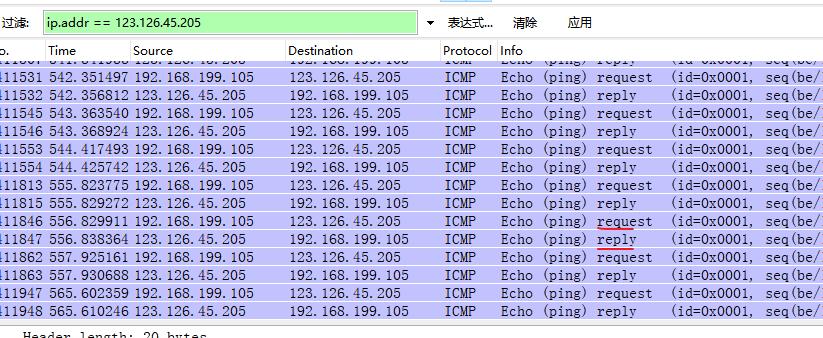
可以看到发送ping 的ICMP协议请求,并且是一个请求 一个响应。
增加数据包发送的大小,超过1500 ,触发数据包的分片
1 | ping sina.com.cn -l 2000 |
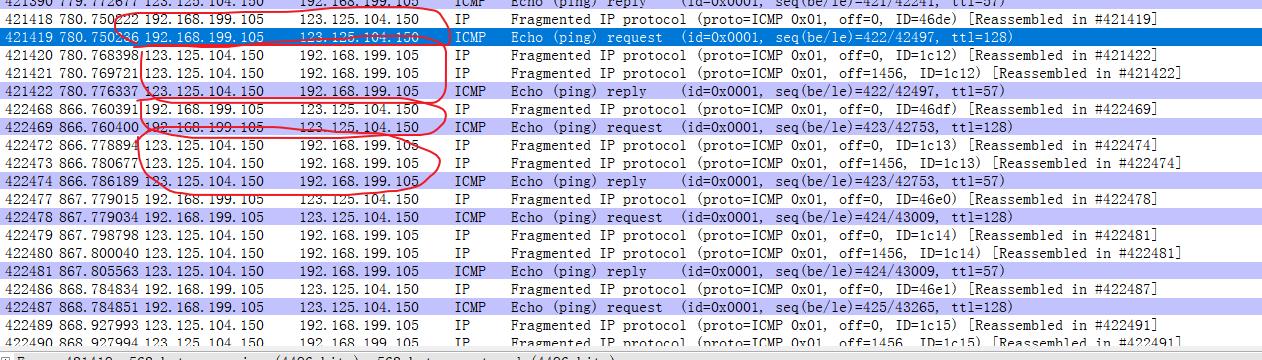
可以看到请求的时候分了2个包,响应的时候分了3个包。
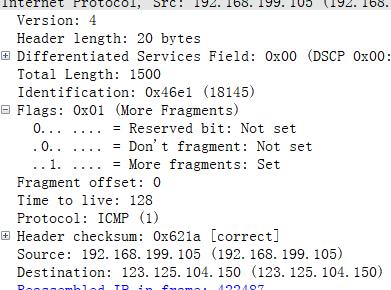
并且可以看到 fragment offset 数据包的字节偏移。 flags 查看是否是最后一个数据包。
TTL 测试
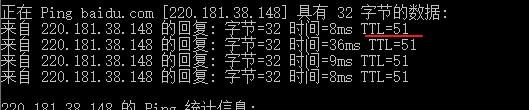
1 | ping baidu.com |
得到的TTL是 51,那么可以得到到百度的服务中转了14个左右的路由器。
TTL 的超时是由对应的路由器响应的。
所以:
1 | ping -i 1 baidu.com |
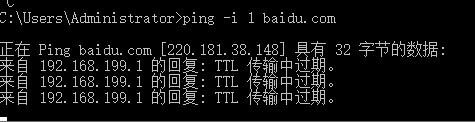
1 | ping -i 2 baidu.com |
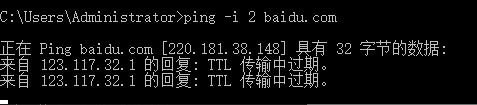
可以看到不同的ttl过期是由不同的路由器回复的。是一级一级进行响应的。
网络工具
- 查看ping支持的更多选择
1 | ping /? |
- tracert 命令
用来追踪请求链路
1 | tracer baidu.com |
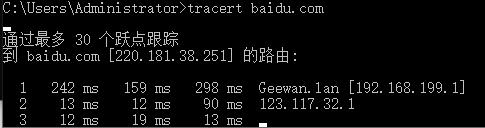
- pathping 命令
1 | pathping baidu.com |

