生产者
编写生产者代码
- 引入客户端依赖包
1
2
3
4
5
6
7
|
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
|
- 编写生产者代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop1:9092,hadoop2:9092,hadoop3:9092");
// key value 序列化类
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
Future<RecordMetadata> send = kafkaProducer.send(new ProducerRecord<>("test_01", "message"));
try {
RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata.topic());
System.out.println(recordMetadata);
} catch (InterruptedException interruptedException) {
interruptedException.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
kafkaProducer.close();
|
主要配置了broker 地址,key 和value 的序列化方法。
- 通过执行命令行监听消息
1
| kafka-console-consumer.sh h --bootstrap-server 192.168.1.103:9092 --topic test_01
|
返回的消息中,RecordMetadata 能看到发送的相关信息。
- RecordMetadata recordMetadata = send.get();
- String topic = recordMetadata.topic();
- long offset = recordMetadata.offset();
- int partition = recordMetadata.partition();
- int keySize = recordMetadata.serializedKeySize();
- int valueSize = recordMetadata.serializedValueSize();
- long timestamp = recordMetadata.timestamp();
同步或异步发送
默认的发送完成后,返回一个Future对象,默认是异步发送消息。在发送完毕后不会阻塞,直到调用get方法。
如果要使用同步发送,只需要在调用的最后调用下get() 方法即可。
1
| RecordMetadata recordMetadata = kafkaProducer.send(new ProducerRecord<>("test_01", "message2")).get(200, TimeUnit.MILLISECONDS);
|
发送回调函数
send() 方法,第二个参数支持传入一个callback 参数来实时监听消息的发送成功和失败。
1
2
3
4
5
6
7
| Future<RecordMetadata> send = kafkaProducer.send(new ProducerRecord<>("test_01", "message3"), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println(e);
System.out.println(recordMetadata);
}
});
|
ProducerRecord 更多参数
1
2
| public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers) {
|
- topic topic信息
- partition 分区id
- timestamp 记录的时间戳,如果是空,那么就是系统时间
- key 记录的key
- value 记录的消息内容
- headers 传递header信息
只有 topic 和vlaue 是必须需要传的
分区
为了提高吞吐量,需要将消息分区。
- 创建一个多个分区的topic
1
| kafka-topics.sh --bootstrap-server 192.168.1.103:9092 --create --partitions 4 --replication-factor=2 --if-not-exists --topic par_test
|
指定分区数量为4 ,那么 0 1 2 3 为4个分区的序列号。
- 监听4个分区的消息
1
2
3
4
5
6
7
8
9
|
kafka-console-consumer.sh h --bootstrap-server 192.168.1.103:9092 --partition 0 --topic par_test
kafka-console-consumer.sh h --bootstrap-server 192.168.1.103:9092 --partition 1 --topic par_test
kafka-console-consumer.sh h --bootstrap-server 192.168.1.103:9092 --partition 2 --topic par_test
kafka-console-consumer.sh h --bootstrap-server 192.168.1.103:9092 --partition 3 --topic par_test
|
- 编写生产者代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop1:9092,hadoop2:9092,hadoop3:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
for (int i = 0; i < 10; i++) {
Integer partition = i % 4;
kafkaProducer.send(new ProducerRecord<>("par_test", partition, null, "message" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null){
System.out.println(metadata.partition());
System.out.println(metadata.offset());
}
}
});
}
kafkaProducer.close();
|
可以看到最终各个监听的控制台,分别监听到各自分区的消息;




默认分区逻辑
查看 KafkaProducer 查看分区的逻辑。
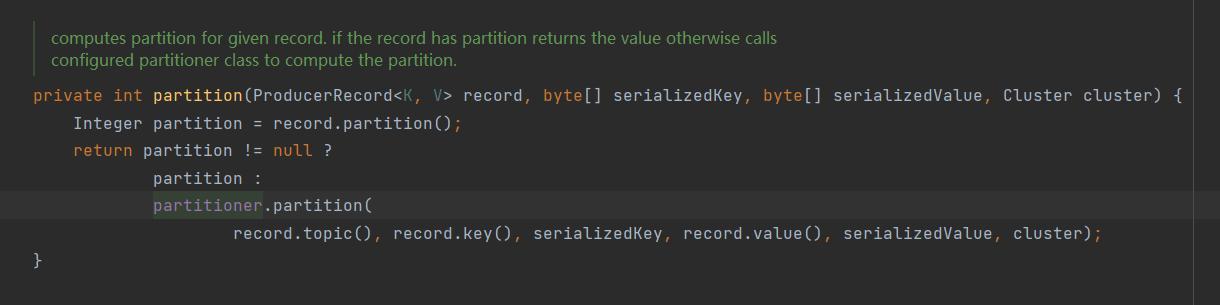
主要逻辑是,首先如果record 上有指定的分区id ,那么使用指定的分区id 。如果没有的话,那么
调用一个 Partitioner 的 partition 方式。
org.apache.kafka.clients.producer.Partitioner 是一个分区的接口。
默认的实现是 org.apache.kafka.clients.producer.internals.DefaultPartitioner
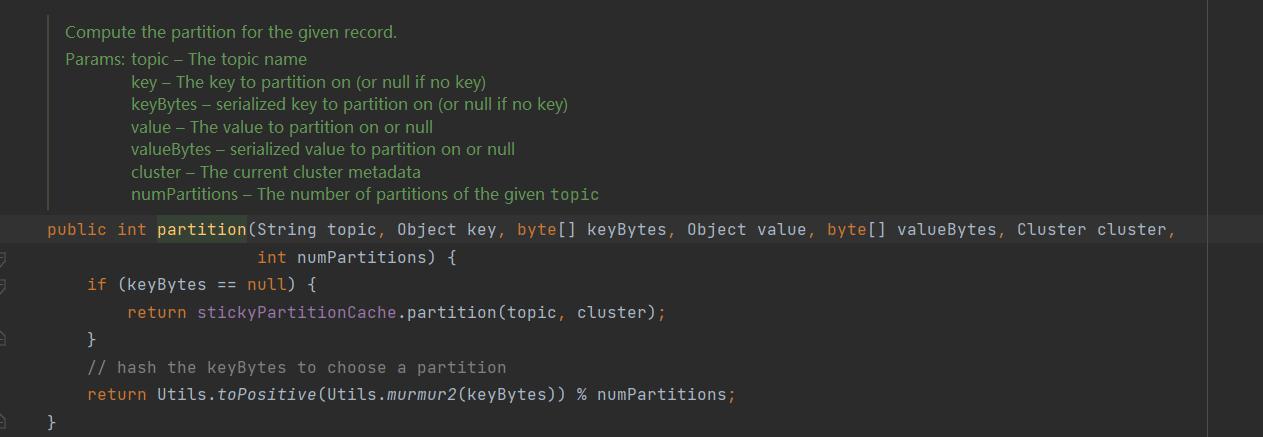
查看默认的分区方式可以看到。
如果有传入key 那么使用对key 进行hash 取模的方式进行hash。
如果没有传入key 那么使用 StickyPartitionCache 针对分区进行粘性分区,随机选择一个分区后,就黏住了,一直向这个分区发送,当满了后(指的是发送的批次数据满了后),再发送别的分区。
所以整体默认区分逻辑为;
- 优先使用传入的分区号码
- 优先使用key hash取模
- 最后使用粘性分区。
自定义分区
自定义分区非常简单,就是定义一个 Partitioner 的一个实现类,然后将自定义的分区类 指定给producer即可。
- 自定义分区类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 1;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
|
- 指定配置类
1
2
3
|
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.kafka.hello.CustomPartitioner");
|
- 发送消息
1
2
3
4
5
6
7
8
9
10
| kafkaProducer.send(new ProducerRecord<>("par_test","message" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null){
System.out.println(metadata.partition());
}
}
});
|
注意:构造ProducerRecord 的时候的partion 要设置为null。即不指定才行。


