kafka(五)kafka的broker的执行流程和参数配置
broker
zookeeper 中的存储信息

- admin
管理相关的节点,目前里面有个删除topic节点,应该是各个节点监听删除事件

- brokers
brokers 相关的节点

- ids 记录了各个 broker的id,及各个节点的id 的相关信息。


seqid
topics

节点下保存着各个topic信息和分区信息。
topics/{topicName}/partitions/pid/state
记录了各个分区节点的状态信息。

cluster
集群的相关信息。

- config
记录了配置信息,下面有多个节点。

consumers
消费者相关信息
controller

{“version”:1,”brokerid”:2,”timestamp”:”1657182918568”}
主要标记了谁是集群的控制者。leader。
isr_change_notification
isr改变相关的通知节点
log_dir_event_notification
当某个Broker上的LogDir出现异常时(比如磁盘损坏,文件读写失败,等等异常): 向zk中谢增一个子节点/log_dir_event_notification/log_dir_event_序列号 Controller监听到这个节点的变更之后,会向Brokers们发送LeaderAndIsrRequest请求; 然后做一些副本脱机的善后操作
- latest_producer_id_block
保存producer id块
broker 流程
broker 大体流程
- 系统启动的时候,因为每个broker id 都是唯一的,会向 broker/ids 中注册各自的broker节点信息。 比如:[0,1,2]
- 同时各个broker节点的controller 向 zk 的 controller 节点注册 id 信息。 {“version”:1,”brokerid”:2,”timestamp”:”1657182918568”} 第一次注册的为主要的broker 控制节点。
- 控制节点(首先注册 controller 的broker节点)监听 broker 节点的变化信息。由controller 来控制每个topic的分区的选举,将节点的状态信息isr 等信息,写入到 /brokers/topics/{topic}/{index}/state “leader”0,:,”isr”:[0,1,2]
- 各个节点的额controller 向zk 同步信息。
- 当broker 的某个节点挂了,那么 brokers/ids 节点 数据将发生变更。 主 controler 监听到节点数据发生变化,获取isr信息,选举新的leader信息。在存活的ar(分区中的所有副本统称为 AR (Assigned Replicas)) 中轮询选举。
follower 和 leader 故障
LEO (log end offset):每个副本中的最后一个offset。
HW (high wateremark): 所有副本中最小的LEO。
如果当一个follower挂了,那么follower 被踢出ISR队列。leader 和follower 继续接收数据。
follower 恢复后,需要和leader 的数据同步到下数据。每个节点都存储了LEO 和HW 信息。此 follower 根据自身的HW 后面的数据都丢弃掉,然后从leader同步数据,直到同步到该follower 的LEO 大于等于该分区的HW后,也就是数据追平了,就可以加入ISR队列了。
如果当一个Leader 挂了,那么从ISR队列中选举一个新的Leader。
为了包装数据的一致性,其他的follower 会截取掉各自log 高于HW部分的数据,然后从新的leader中同步数据,这个过程中可能存在数据丢失。
broker 的一些参数
replica.lag.time.max.ms ISR中,Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值,默认 30s。
auto.leader.rebalance.enable 默认是 true。 自动 Leader Partition 平衡。
leader.imbalance.per.broker.percentage 默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发leader的平衡。
leader.imbalance.check.interval.seconds 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。
log.segment.bytes Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G。
log.index.interval.bytes 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。
消息日志文件分为2部分,一个是一个段一个段的日志消息文件,一个是为了快速查找消息的索引文件。
log.retention.hours Kafka 中数据保存的时间,默认 7 天。
log.retention.minutes Kafka 中数据保存的时间,分钟级别,默认关闭。
log.retention.ms Kafka 中数据保存的时间,毫秒级别,默认关闭。
log.retention.check.interval.ms 检查数据是否保存超时的间隔,默认是 5 分钟。
log.retention.bytes 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的 segment。
log.cleanup.policy 默认是 delete,表示所有数据启用删除策略;如果设置值为 compact,表示所有数据启用压缩策略。
log.flush.interval.messages 强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。
log.flush.interval.ms 每隔多久,刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理。
num.io.threads 默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%。
num.replica.fetchers 副本拉取线程数,这个参数占总核数的 50%的 1/3
num.network.threads 默认是 3。数据传输线程数,这个参数占总核数的50%的 2/3 。
Leader Partition 负载平衡
默认leader 是均匀分布在不同的broker上的,但是可能出现broker宕机再恢复,导致leader过于集中的出现在某些机器上,恢复的节点都是follower节点了。
那么kafka支持对节点的leaer节点执行自动的负载均衡操作,需要执行一些配置就可以定期检查节点的leader分布是否均衡。
参数配置:
- auto.leader.rebalance.enable 默认是true ,默认开启,开启会有一定的性能影响。
- leader.imbalance.per.broker.percentage 默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。
- leader.imbalance.check.interval.seconds 单位秒,也就是检查时间间隔。
文件存储机制
对于每个topic的每个分区都有一个这个分区的特定的日志文件目录。
比如topic 为 onetopic ,那么分区0 到 3 的目录分别是 onetopic-0 onetopic-1 onetopic-2 onetopic-3
简而言之,各个分区的数据是独立存储的。
每个分区目录下有这么几类文件
- .log
log 日志数据文件
- .index
日志的索引文件
- .timeindex
时间戳索引文件
其中每个日志文件根据配置(log.segment.bytes)分为一个一个的小段(segment),并且会执行预先分配磁盘空间,即使没有数据。为了提交磁盘的顺序写的性能。
index 和log 文件的命名都是以数字来命名的,以当前的segment的第一个消息的offset命令。
index和 log 文件是如果存储的
log 文件是存储了真正的消息的数据。内部有消息文件,消息的offset,这里存储的offset是文件的相对offset。
index 文件是根据配置 (log.index.interval.bytes=4kb) ,当向log写入4kb的数据后,向index写入一条数据,为了能够快速定位数据记录的位置。
log.segment.bytes Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G。
log.index.interval.bytes 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。
消息日志文件分为2部分,一个是一个段一个段的日志消息文件,一个是为了快速查找消息的索引文件。
文件的清理
可以通过几个参数修改文件日志保存的时间。
log.retention.hours
log.retention.minutes
log.retention.ms,最高优先级毫秒。
log.retention.check.interval.ms 负责设置检查周期,默认 5 分钟。
当触发了文件清理后,有2种文件清理策略.
- delete
log.cleanup.policy = delete
删除文件,将满足条件的文件直接删除。
默认情况下会校验segment 时间过期的文件直接删除segment。(segment时间为最后一个记录的时间。
同时还有一个基于空间删除的选择,如果同时开启了 log.retention.bytes。如果log.retention.bytes = -1 表示未开启, 如果 log.retention.bytes 配置了,那么检查所有的日志大小是否超过了这个配置的大小,超过了,删除最早的segment文件。一般此选项不开启。
- compact
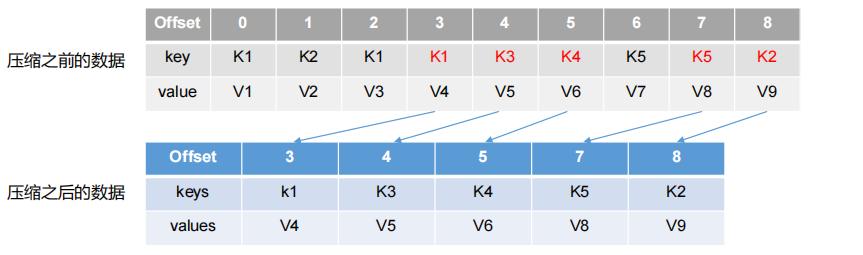
log.cleanup.policy = compact
压缩文件,即不对文件进行删除,而是将相同的key 的消息日志文件,进行合并,只保留最新的一个版本,减少磁盘占用。