
k8s(八) 使用 StatefulSet 部署有状态服务
StatefulSet 有状态的服务
前面提到的服务都是无状态的服务,可以任意进行伸缩的服务,而真实的场景下很多服务是具有状态的,比如mysql 主从集群,有的是主节点,有的是从节点等。StatefulSet 就是用来管理有状态的应用的服务的。
既然服务有状态,那么在执行服务pod 部署的时候就需要有一些限制
稳定的、唯一的网络标识符。
稳定的、持久的存储。
有序的、优雅的部署和缩放。
有序的、自动的滚动更新。
StatefulSet 具有如下特性
StatefulSet里的每个Pod都有稳定、唯一的网络标识,可以用来 发现集群内的其他成员。假设StatefulSet的名称为kafka,那么第1个Pod 叫kafka-0,第2个叫kafka-1,以此类推。
每一个pod都有一个唯一的域名
StatefulSet控制的Pod副本的启停顺序是受控的,操作第n个Pod 时,前n-1个Pod已经是运行且准备好的状态。
StatefulSet里的Pod采用稳定的持久化存储卷,通过PV或PVC来实现,删除Pod时默认不会删除与StatefulSet相关的存储卷(为了保证数据的安全)。
以nginx为例说明:
1 | apiVersion: v1 |
应用此文件,可以看到生成的3个pod.并且名称是有序的

StatefulSet Pod 具有唯一的标识,该标识包括顺序标识、稳定的网络标识和稳定的存储。 该标识和 Pod 是绑定的,不管它被调度在哪个节点上。
DaemonSet
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。
特点:
- 每个node 上只有一个
- 当集群有新的节点加入会给新加入的节点加入pod 会给节点创建deamonset
首先将集群中的一台机器剔除集群

目前有2个work节点
1 | //删除节点2 |
新创建一个deamonset
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
查看运行的pod,注意namespace
1 | kubectl get pod -n kube-system -o wide | grep fluentd-elasticsearch |

让node2 现在也加入集群
1 | //master 节点打印连接信息 |
1 | //node2 重置 |
会看到再给新的节点自动创建此deamonset

Job
job资源对象用于定义批处理类型的应用。通过job定义一组任务可以串形或并行的执行。
job 去处理一批工作项(work item), 处理完成后,整个批处理任务结束。
批任务分为几种模式
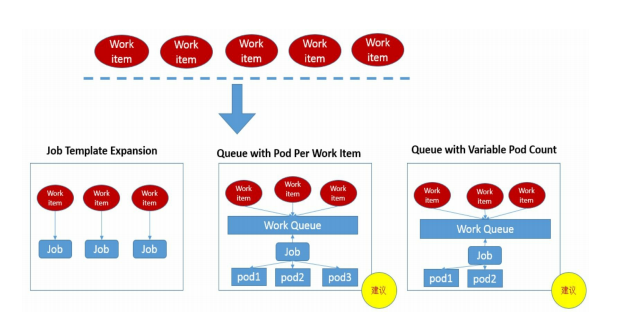
Job Template Expansion模式
一个job对象对应一个workitem ,适合workitem 比较少,并且处理的数据量大的场景
Queue with Pod Per Work Item模式
采用一个任务队列存放 Work item,一个Job对象作为消费者去完成这些Work item,在这种模式 下,Job会启动N个Pod,每个Pod都对应一个Work item
Queue with Variable Pod Count模式
采用一个任务队列存 放Work item,一个Job对象作为消费者去完成这些Work item,但与上面 的模式不同,Job启动的Pod数量是可变的
根据并行度又分为几种类型
Non-parallel Jobs
一个job 启动一个pod,除非pod异常才会重启pod ,pod 执行完毕则执行结束。
Parallel Jobs with a fixed completion count
使用固定的pod 数量,可以通过修改 Job的.spec.completions参数来定义
Parallel Jobs with a work queue
多个pod 通过work queue 队列获取的方式,这种方式会有多个pod 从队列中拉取需要处理的workitem
,当队列中没有work item了 ,pod就会结束,当所有的pod结束了,此job就结束了。
示例job:
1 |
|
1 | kubectl apply -f job.yaml |
可以看到job执行完毕;

出现拉取镜像卡住的情况,定义 imagePullPolicy: IfNotPresent
Corn Job 定时的job
注意:Kubernetes 服务器版本必须不低于版本 v1.21.
此job可以使用job表达式来定义job
示例:
1 | apiVersion: batch/v1 |
