
k8s(四)pod对象的详细说明
pod详解
pod k8s中服务执行的最小单位,接下来详细的说明跟pod相关的自定义配置和原理机制。
pod 生命周期
执行 kubectl get pod 查看pod的信息,可以看到有个状态信息,里面表示了当前pod的状态。
1 | [root@master ~]# kubectl get pod |
pod 有多种声明周期状态,下面详细说明
pod 重启策略
pod 内有个 RestartPolicy 字段用于控制pod 内所有容器的重启策略;
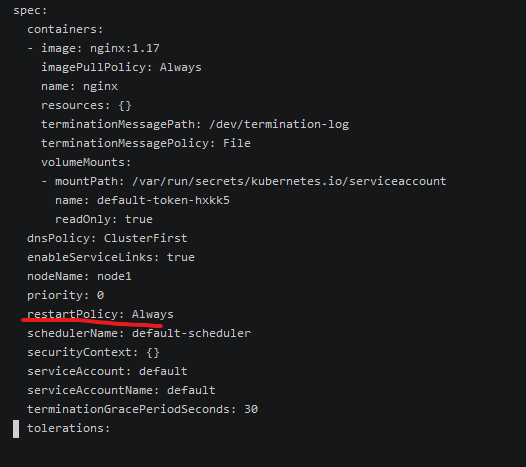
几种类型说明:
默认值为Always。
Always:当容器失效时,由kubelet自动重启该容器。
OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器。
Never:不论容器运行状态如何,kubelet都不会重启该容器。
pod 健康检查机制
如何定义pod 是否监控,这个定义k8s 无法为我们做这个判断,难度pod中的业务容器正确运行就算健康吗?这些健康的定义有时候需要我们根据业务的定义来做自定义的判断
k8s 提供了两类探针来检查
- LivenessProbe
判断容器状态是存活就为可用状态,如果没配置就一直认为是可用状态。
- ReadinessProbe
用于判断服务是否可用来判断服务是否可用;
对于上面的2种方式,都可以通过三种操作方式来实现
ExecAction 通过在容器内执行命令的方式,返回0 表示健康,否则不健康
示例:
- 创建一个pod
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: centos:7
args:
- /bin/sh
- -c
- touch /healthy; sleep 30; rm -rf /healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /healthy
initialDelaySeconds: 5
periodSeconds: 5执行apply 创建pod
1
kubectl apply -f exec-action.yml
因为默认的重启策略是 restart 。查看pod 的详细信息可以看到

可以看到pod 被重启;
TCPSocketAction 向容器内建立tcp连接,如果端口正常表示容器正常
配置
1 | livenessProbe: |
监听特定的端口
向特定方法发送http 请求,如果请求正常表示pod正常
示例:表示向特定端口请求返回正常,表示服务正常
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: k8s.gcr.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
pod 的配置管理 configMap
configmap 为容器内的配置的集中化管理。
configMap 是一个key:value 格式的键值对,一般存储安全性不高的配置信息,(安全性要求高的密码等信息使用secret 存储)。
一般由这么几种常用的方式
- 在容器命令和参数内
- 容器的环境变量
- 在只读卷里面添加一个文件,让应用来读取
- 编写代码在 Pod 中运行,使用 Kubernetes API 来读取 ConfigMap
- 有一个spring的配置文件

从文件中生成配置
1
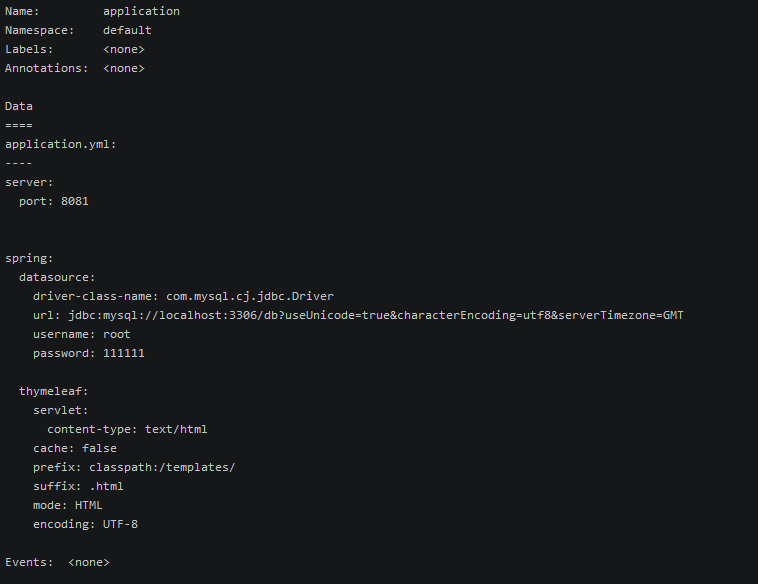
kubectl create configmap application --from-file=./application.yml
查看已经创建的configmap
1
2kubectl get configmap
查看详细的信息
1
2kubectl describe configmap application
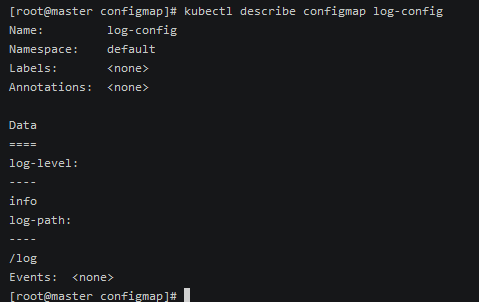
支持直接使用键值对生成configmap ,这种是不使用文件的方式直接写入配置
1
2kubectl create configmap log_config --from-literal=log-level=info --from-literal=log-path=/log
- pod 中使用configmap作为环境变量
k8s中支持一个envFrom 的属性,支持直接将一个配置文件的key vlaue作为环境变量
创建一个打印env的pod
1 | apiVersion: v1 |
envFrom. configMapRef 表示从哪个配置源中获取环境变量
执行此文件
1 | kubectl apply -f env-pod.yaml |
会看到pod在执行,执行完毕后变成完成状态.
查看日志
1 | kubectl logs env-test-pod |
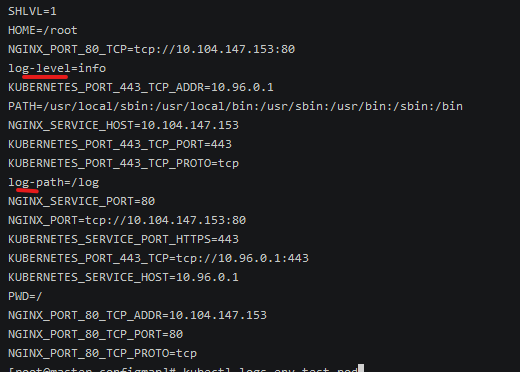
可以看到配置的环境变量已经在pod中了
文件挂载的方式使用configmap
编写一个pod 来读取挂载的文件
1
vim configmap-mount.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18apiVersion: v1
kind: Pod
metadata:
name: configmap-mount-pod
spec:
containers:
- name: configtest
image: busybox
command: [ "/bin/sh", "-c", "cat /usr/application.yml" ]
volumeMounts:
- name: application
mountPath: /usr
volumes:
- name: application
configMap:
name: application
restartPolicy: Never主要通过挂载的方式 ,查看挂载的信息。
1
2kubectl apply -f configmap-mount.yaml
执行完毕后,查看日志
1
2kubectl logs configmap-mount-pod
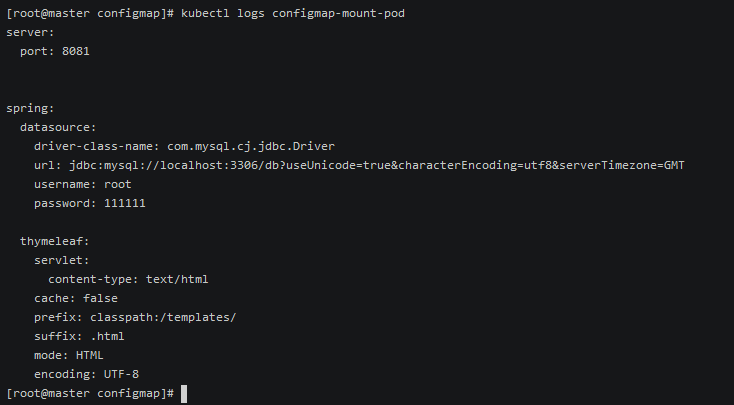
configMap 的使用限制
- ConfigMap必须在Pod之前创建。
- ConfigMap受Namespace限制,只有处于相同Namespace中的 Pod才可以引用它。
- kubelet只支持可以被API Server管理的Pod使用ConfigMap
- 在Pod对ConfigMap进行挂载(volumeMount)操作时,在容器内部只能挂载为“目录”,无法挂载为“文件”。
pod 的安全配置管理 Secret
Secret的主要作用是保管私密数据,比如密 码、OAuth Tokens、SSH Keys等信息。将这些私密信息放在Secret对象上存储比configmap安全。
Kubernetes 提供若干种内置的类型,用于一些常见的使用场景。 针对这些类型,Kubernetes 所执行的合法性检查操作以及对其所实施的限制各不相同。
官网详细链接 https://kubernetes.io/zh/docs/concepts/configuration/secret/
以 Opaque Secret 类型的数据作为pod的环境变量
1 | kubectl create secret generic test-secret |
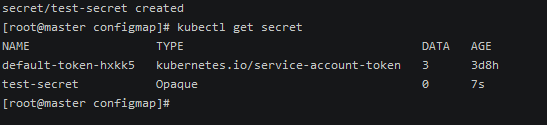
编辑信息:
1 | kubectl edit secret test-secret |
以为类型是 Opaque 可以设置任意数据,其他类型格式有限制
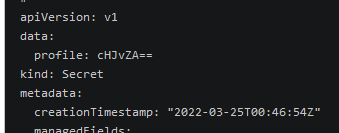
注意对应的vlaue 需要经过base64编码
pod 通过挂载的方式使用
1 | apiVersion: v1 |
1 | kubectl apply -f secret-env.yml |
查看日志信息:
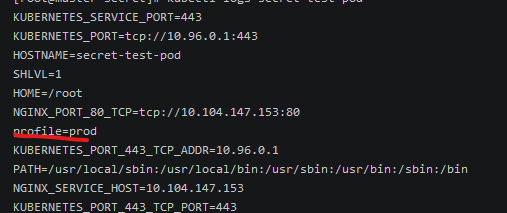
pod 调度
有时候我们需要将特定的pod调度到特定的node 上,或者优先调度到特定的node 上。我们也可以指定一些策略来调整和控制。
pod一般由deployment 来进行管理,而deployment中的pod template 中可以通过配置pod的调度相关的策略;
NodeSelector 调度
针对资源对象可以添加一些标签,可以通过标签选择器来选定测定的资源。下面以NodeSelector 来指定pod的部署的node节点;

给node1 打上特定的标签
1 | kubectl label node node1 disk=ssd |
标记node1 的节点 磁盘是ssd 的,现在需要将nginx 的一个部署都调度到磁盘为ssd的上面;
编辑部署
1 | kubectl edit deploy nginx-deployment |
编辑 deploy中的pod 模板节点的 template.spec.containers.nodeSelector

可以看到pod的分布
1 |
|

Node亲和性调度 (NodeAffinity属性)
(官网链接)https://kubernetes.io/zh/docs/tasks/configure-pod-container/assign-pods-nodes-using-node-affinity/
上面的nodeSelector是强制性的策略,是一定要选择到特定的节点的。
k8s同样提供了亲和性的策略,可以具有一定的容错性。会更加的灵活和可靠。
其中提供了多种策略。
强制调度 requiredDuringSchedulingIgnoredDuringExecution
此策略表示必须,修改配置此策略
kubectl edit deploy nginx-deployment
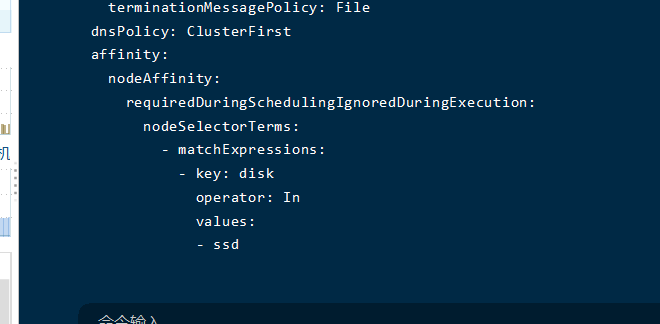
同样会看到节点调用到node1 的节点上;
优先调度 preferredDuringSchedulingIgnoredDuringExecution
不会强制,但会优先调度到某个节点;
当配置不存在的属性的时候会分散调度
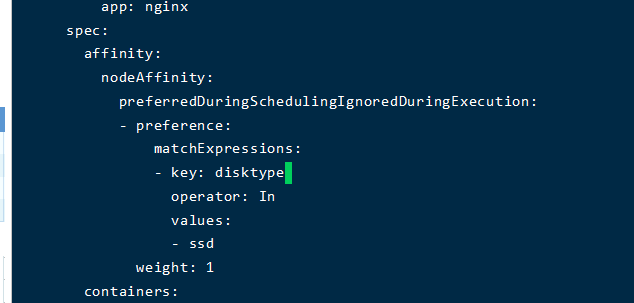

配合优先调度ssd
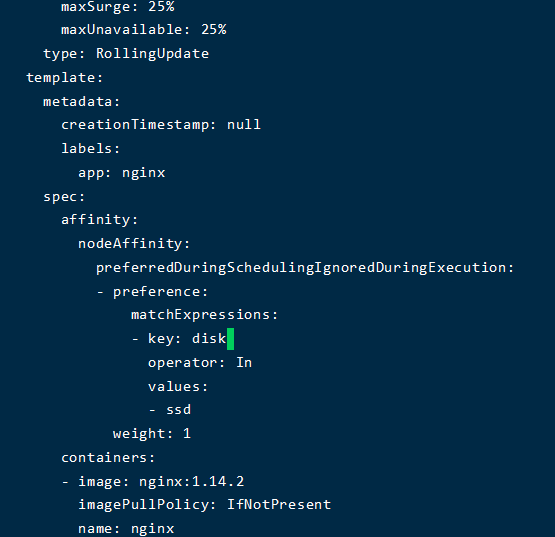
会发现都调度到node1 上了
Pod 亲和性调度 (PodAffinity属性)
NodeAffinity 是为了解决pod 要部署到哪个node 上的。基于的标签是pod的标签;
给目前运行的nginx 设置pod 标签
强制亲和性 requiredDuringSchedulingIgnoredDuringExecution
新创建一个tomcat 部署
1 | kubectl create deploy tomcat8 --image=tomcat:8.0 --dry-run=client -o yaml |
生成文件,并配置 requiredDuringSchedulingIgnoredDuringExecution:
1 |
|
应用此配置,可以看到已经被调度到 node 节点的相同的disk属性的 pod 上了;

topologyKey 的含义是:指的是一个集群中的节点、机架、区域等概念,通过 Kubernetes内置节点标签中的key来进行声明。这个key的名字为 topologyKey,意为表达节点所属的topology范围。其实是node 节点属性;
柔软亲和性 preferredDuringSchedulingIgnoredDuringExecution
和 requiredDuringSchedulingIgnoredDuringExecution的作用一样,区别是 此策略并不是强制的。
Pod 反亲和性调度 (PodAntiAffinity属性)
和pod 亲和性相反,指的是尽量不和某个pod在同一个node上。
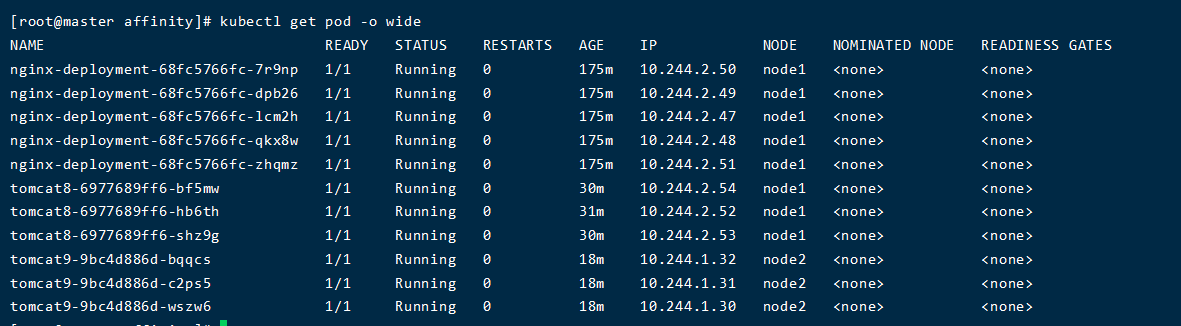
以刚才的例子,修改成反亲和性
1 |
|
tomcat9的区别只是配置成了反亲和性
污点和容忍度 Taints和Tolerations
Taint需要和Toleration配合使用,让Pod避开那些不合适的Node。
Taints 是node的属性;Tolerations 是pod的属性;
具有污点的节点是要避开的,而有对特定污点容忍度的pod可以运行在特定的节点上。
向node1 添加一个污点
1 | kubectl taint nodes node1 key1=value1:NoSchedule |

1 | //去除污点 |
会发现 污点后创建的pod自动避开了污点
给deploy设置容忍度
1 | kubectl edit deploy nginx |
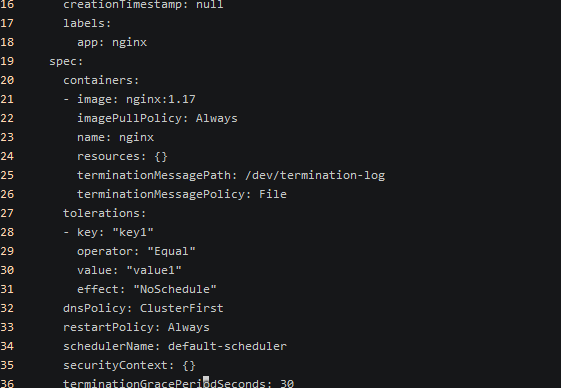
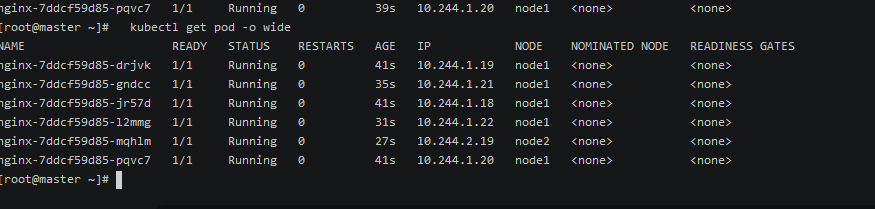
可以看到pod已经优先调度到node1 具有污点的节点上了;
effect 使用 NoSchedule 表示不调度,或者 PreferNoSchedule 表示尽量不调度。
除了我们自定义的污点,k8s也内置了系统运行情况的污点。
node.kubernetes.io/not-ready:节点未准备好。这相当于节点状态Ready的值为 “False“。node.kubernetes.io/unreachable:节点控制器访问不到节点. 这相当于节点状态Ready的值为 “Unknown“。node.kubernetes.io/memory-pressure:节点存在内存压力。node.kubernetes.io/disk-pressure:节点存在磁盘压力。node.kubernetes.io/pid-pressure: 节点的 PID 压力。node.kubernetes.io/network-unavailable:节点网络不可用。node.kubernetes.io/unschedulable: 节点不可调度。node.cloudprovider.kubernetes.io/uninitialized:如果 kubelet 启动时指定了一个 “外部” 云平台驱动, 它将给当前节点添加一个污点将其标志为不可用。在 cloud-controller-manager 的一个控制器初始化这个节点后,kubelet 将删除这个污点。
默认情况下,我们的应用可能因为某个节点有污点而离开,可以有时候比如网络污点是可能恢复的,所以可以配置
tolerationSeconds 来定义在污点能最多待多长时间。
初始化容器 init container
在pod中除了pause 容器和业务容器,还可以定义初始化容器。
初始化容器 可以理解为在pod中的业务容器执行前执行的容器,此容器执行完毕后,业务容器才开始启动。
初始化容器可以做一些资源加载 等相关的操作,为了业务容器而服务。
init container 是一定会执行完毕的,只有执行完毕 ,业务容器才能执行。
init container 重启策略是Never,如果业务容器执行失败,则表示pod执行失败
当定义多个init container 时 ,会一个一个按照顺序执行
下面以nginx为例演示init container
编辑 nginx的deploy信息
1
2kubectl edit deploy nginx
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
5657 spec:
158 containers:
159 - image: nginx:1.17
160 imagePullPolicy: Always
161 name: nginx
162 resources: {}
163 terminationMessagePath: /dev/termination-log
164 terminationMessagePolicy: File
165 volumeMounts:
166 - mountPath: /usr/tmp ## 给业务容器挂载路径
167 name: tmpdir
168 dnsPolicy: ClusterFirst
169 initContainers:
170 - command:
171 - sh
172 - -c
173 - echo echo container running ! && sleep 15
162 resources: {}
163 terminationMessagePath: /dev/termination-log
164 terminationMessagePolicy: File
165 volumeMounts:
166 - mountPath: /usr/tmp
167 name: tmpdir
168 dnsPolicy: ClusterFirst
169 initContainers:
170 - command:
171 - sh
172 - -c
173 - echo echo container running ! && sleep 15 #初始化容器1 执行打印和睡眠
174 image: busybox
175 imagePullPolicy: Always
176 name: echo-container
177 resources: {}
178 terminationMessagePath: /dev/termination-log
179 terminationMessagePolicy: File
180 - command: # 初始化容器2 向指定的目录写个文件
181 - sh
182 - -c
183 - 'touch /usr/tmp/a '
184 image: busybox
185 imagePullPolicy: Always
186 name: create-file
187 resources: {}
188 terminationMessagePath: /dev/termination-log
189 terminationMessagePolicy: File
190 volumeMounts:
191 - mountPath: /usr/tmp
192 name: tmpdir
193 restartPolicy: Always
194 schedulerName: default-scheduler
195 securityContext: {}
196 terminationGracePeriodSeconds: 30
197 volumes: # 定义容器挂载
198 - emptyDir: {}
199 name: tmpdir


可以在状态的这里看到初始化到第一个容器了。
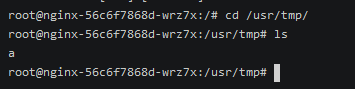
初始化容器写入的文件也被写入。
